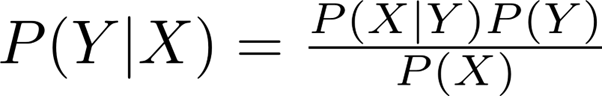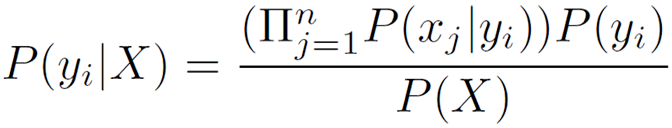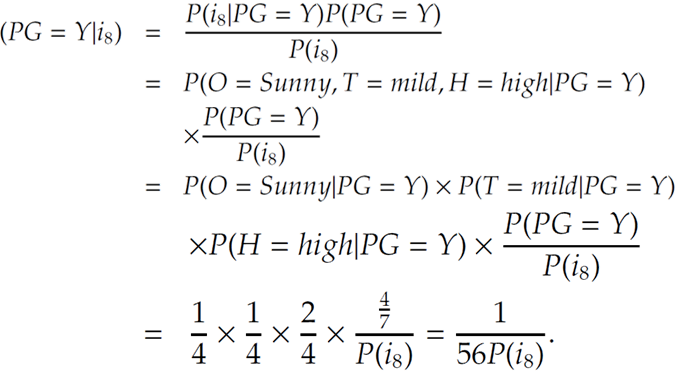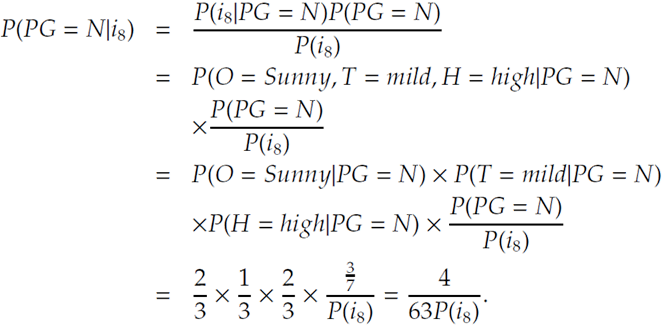결정트리는 이해하기 쉬운 알고리즘으로써, 데이터에 있는 규칙을 학습으로 찾아내 트리 기반의 분류 규칙을 만드는 것이다. 단순하게 말하면 분기문을 만들어 구분한다고 생각하면 되겠다.
결정 트리의 경우 루트노드, 규칙이 있는 서브노드와 결정된 값이 들어있는 리프노드가 있다. 그리고 새로운 규칙이 추가될때 이에 기반한 서브트리가 생성된다.
이때, 많은 규칙이 있다는 것은 분류를 결정하는 방식이 복잡하다는 것이고, 이는 과적합, 성능저하의 원인이 된다.
결정트리의 핵심 아이디어는 불순도를 낮추는 것에 있다. 불순도란 정보의 복잡도(얼마나 균일한가)를 의미하며, 불순도를 수치화한 값에는 지니계수(Gini coefficient)와 엔트로피(Entropy)가 사용된다.
아무래도, 동일한 데이터에서도 결정트리는 여러 개가 나올 수가 있는데, 여기서 불순도를 이용해 더 효과적인 결정트리를 결정할 수 있다.
subNode에서 데이터가 분리되었을 때, 더 순도가 높은 데이터가 많이 나오게 되는 속성이 더 효과적이라고 할 수 있으며, 이때 순도가 높다는 것은 분류된 레이블 값이 동일한 것, 즉, 레이블 값이 다 같은 것을 말한다.
이때, 분류가 완료된 리프노드의 엔트로피는 0이다.
Decision Tree의 성능측정은 entropy(T)를 통해 이뤄지며 entropy(T)= -p+log(p+) -p-log(p-)이다.
이때, p+, p-는 각각 positive position(순도가 pure한 것/전체), nagative position(순도가 pure하지 않은 것/전체)를 말한다.
예를 들어 10개 데이터의 클레스를 분류한 결과, 7개는 예측이 잘 되지만 3개는 안된다면
p+, p-는 각각 [7+, 3-]이고, entropy(T)= -(7/10)log(7/10)-(3/10)log(3/10)=0.881 이다. (entropy 는 0to1 이다)
조금 더 살펴보자면, 결정트리 알고리즘에는 ID3, CART가 있는데, 이때 ID3은 엔트로피를 사용하고, CART는 지니계수를 사용한다. (이 내용 공부후 추가할 것)
랜덤 포레스트
랜덤 포레스트란 배깅을 사용하는 앙상블으로써, 배깅은 같은 알고리즘으로 여러 개의 모델을 만들어서 보팅으로 최종 결정하는 알고리즘이다.
기본적인 개념은 여러 개의 결정트리 모델이 전체 데이터를 샘플링해 개별적으로 학습을 수행 한 뒤, 모든 분류기가 보팅을 통해 예측 결정을 하는 방식이다.
이때, 보팅이란 여러개의 모델이 학습하고 예측한 결과를 보팅으로 최종 예측하는 것으로써, 하드보팅과 소프트 보팅이 있다.
하드 보팅은 일종의 다수결 원칙으로, 다수의 모델이 결정한 예측값을 최종 보팅값으로 선정하는 것이고, 소프트 보팅은 모델의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이 중 가장 확률이 높은 레이블 값을 최종 보팅 결과값으로 선정하는 것으로써, 일반적으로 소프트 보팅이 사용된다.
랜덤 포레스트의 모델별 알고리즘은 결정트리이지만, 각각의 모델이 학습하는 데이터는 전체 데이터에서 일부가 중첩되도록 샘플링된 데이터셋이다. 이렇게 여러 개의 데이터셋을 중첩되게 분리하는 것을 부트스트레핑(bootstrapping)분할 방식이라고 하며,
‘Model evaluation, model selection, and algorithm selection in machine learning Part II – Bootstrapping and uncertainties, Setabstian Raschka
이렇게 부트스트레핑으로 분할된 데이터셋에 결정트리 모델을 각각 적용하는 것이 랜텀 포레스트이다.
GBM
다음으로 GBM을 살펴보면
부스팅 알고리즘이란 여러 개의 약한 학습기를 순차적으로 학습-예측하며 잘못 예측된 데이터에 가중치를 부여하여 오류를 개선하며 학습하는 것이다.
대표적으로 AdaBoost와 GradientBoost가 있다.
KNN
KNN을 먼저 설명하자면 이건 매우 쉽다.
간단하게 가장 가까운 점 몇개를 가지고 분류하겠다는 문제.
http://dmml.asu.edu/smm
http://dmml.asu.edu/smm
예측하고 싶은 data에서 가장 가까운 k개의 이웃을 구하고, 거리를 measure하고, 그들의 class값을 체크한 뒤 조정해서 예측하는 것이다.
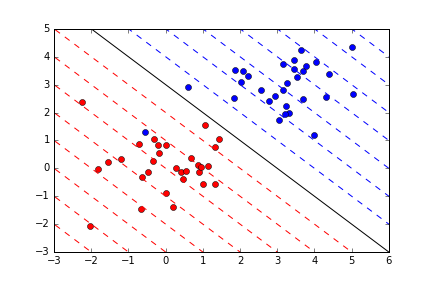
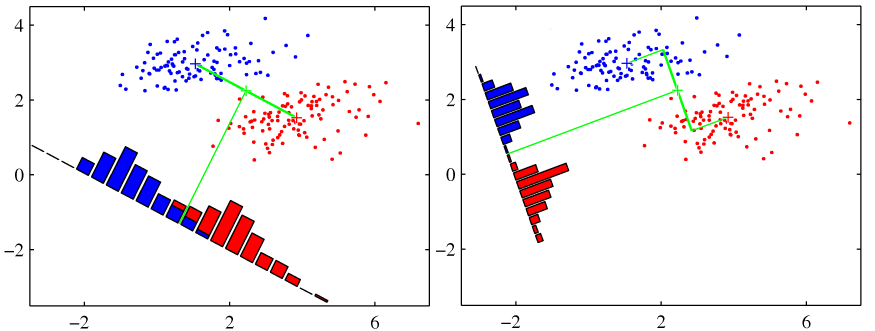
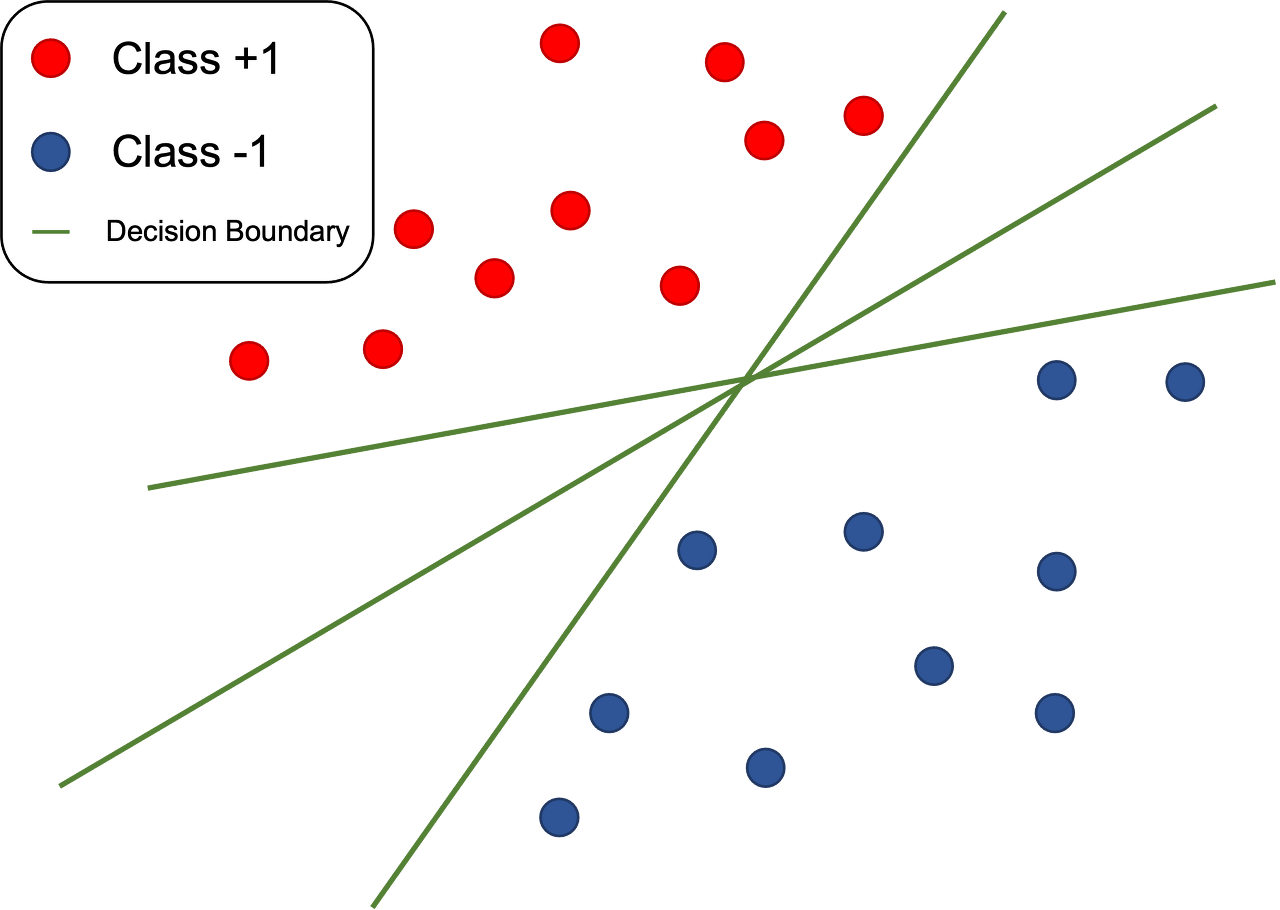
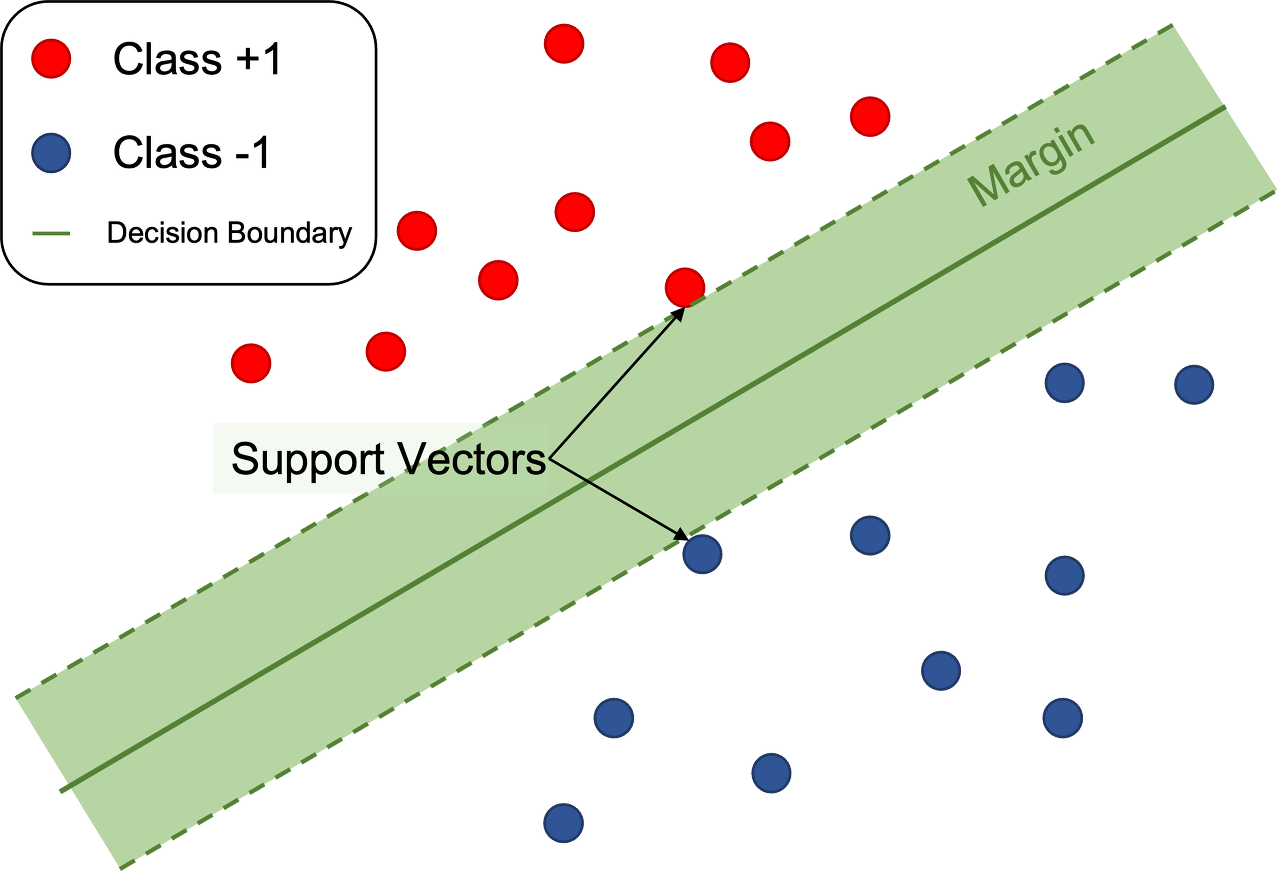
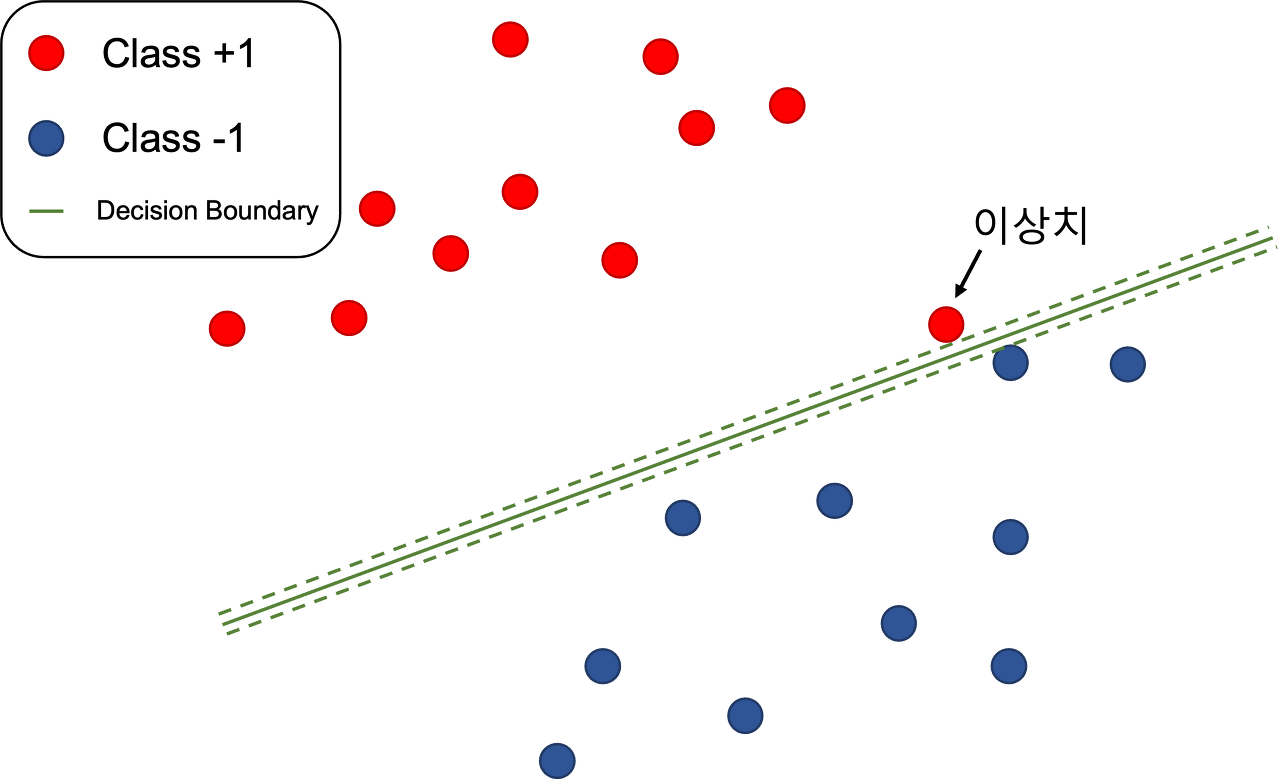
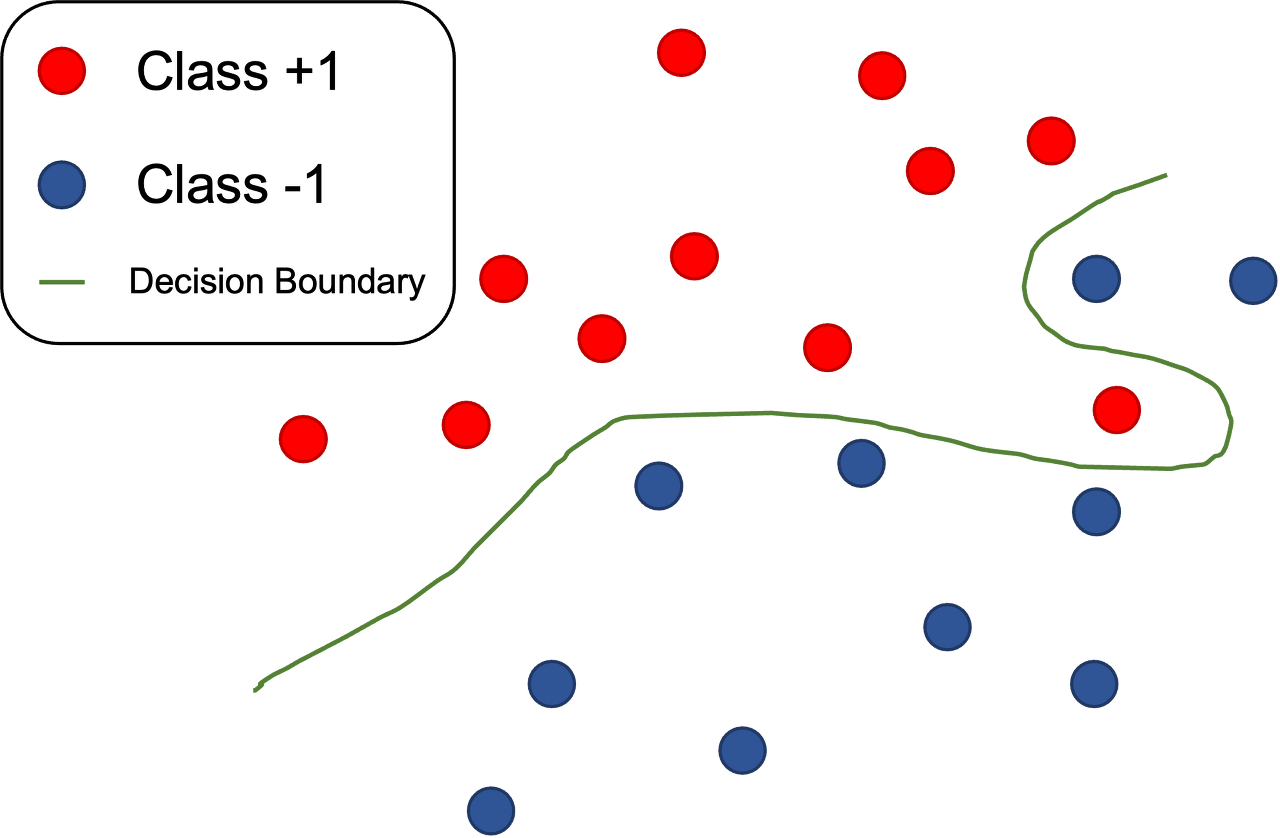
다음이 SVM인데, 이는 기본적으로 그룹을 분리하기 위해, 데이터들과 가장 거리가 먼 초평면을 선택하여 분리하는 방법을 말한다.
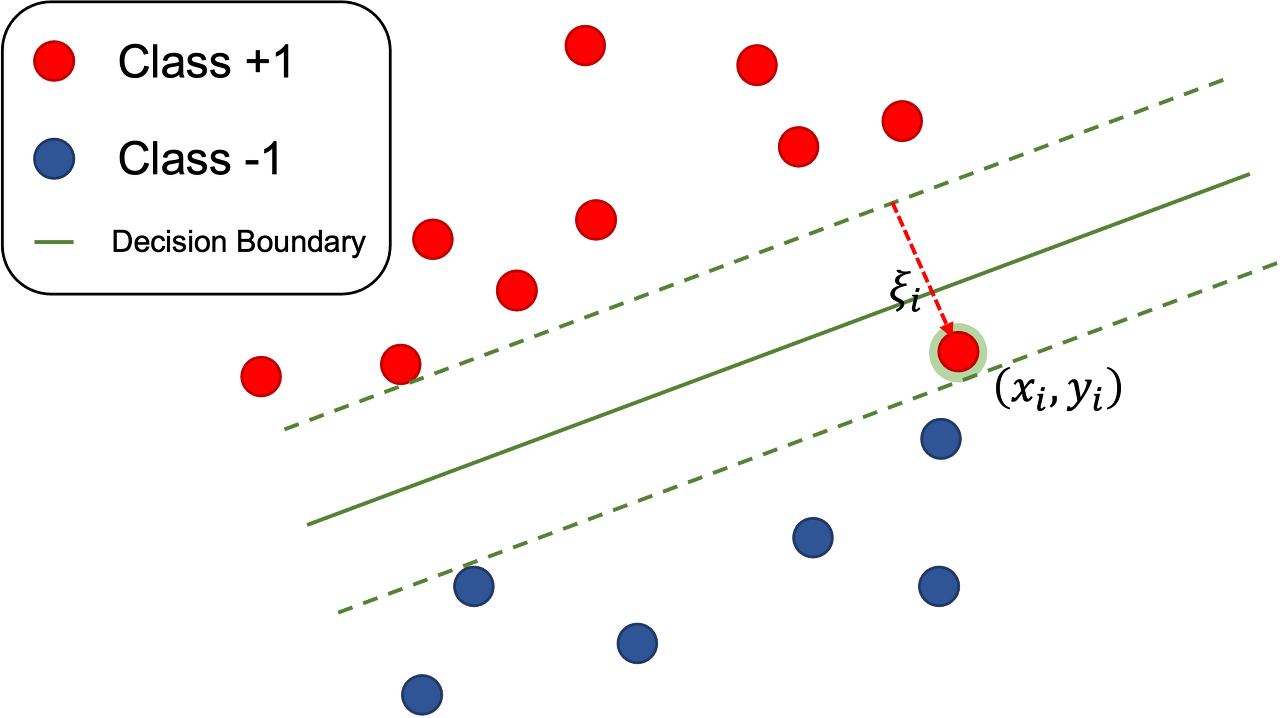
각 훈련 데이터 샘플 마다 잉여 변수를 대응시켜, 샘흘이 마진의 폭 안으로 만큼 파고드는 것을 용인해주는 것이다.
-커널트릭
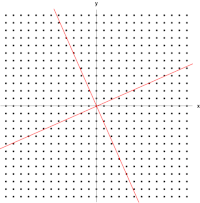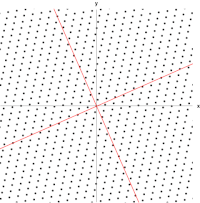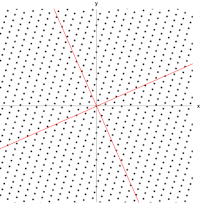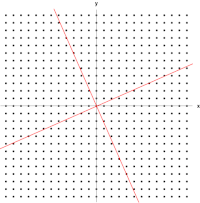
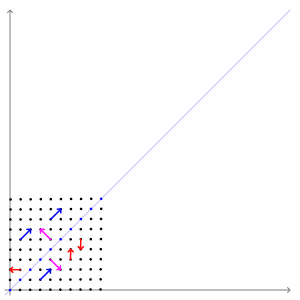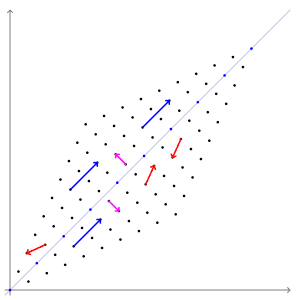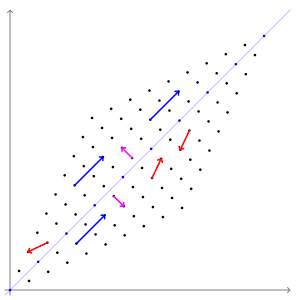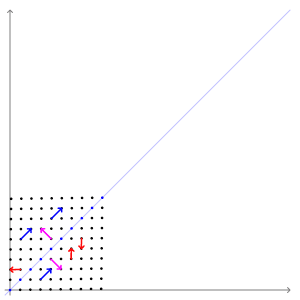
eigen vector을 잘 설명해주는 그림이 있어 위키피디아에서 가져왔다.
In this shear mapping the red arrow changes direction, but the blue arrow does not. The blue arrow is an eigenvector of this shear mapping because it does not change direction, and since its length is unchanged, its eigenvalue is 1 _https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectorsA 2×2 real and symmetric matrix representing a stretching and shearing of the plane. The eigenvectors of the matrix (red lines) are the two special directions such that every point on them will just slide on them.https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectorsThe transformation matrix A = {\displaystyle \left[{}\right]} preserves the direction of purple vectors parallel to v λ=1 = [1 −1] T and blue vectors parallel to v λ=3 = [1 1] T . The red vectors are not parallel to either eigenvector, so, their directions are changed by the transformation. The lengths of the purple vectors are unchanged after the transformation (due to their eigenvalue of 1), while blue vectors are three times the length of the original (due to their eigenvalue of 3). See also: An extended version, showing all four quadrants .https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors
SVM
Naive Bayes
다음으로 Naive Bayes Learning을 살펴보면,
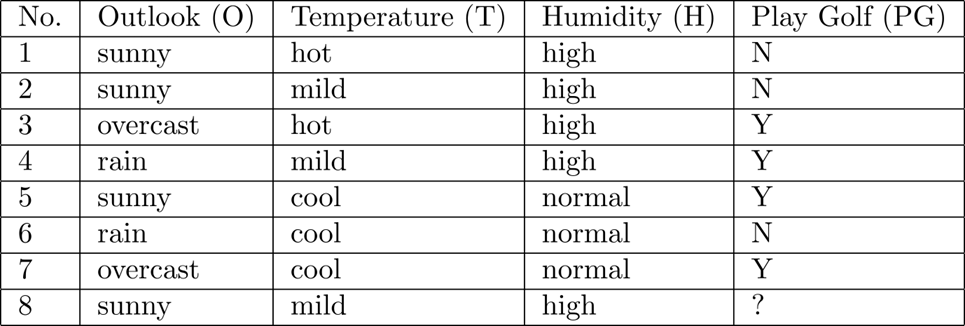
기본적 아이디어는 조건부 확률을 말하는 것으로 예를 들어 2개의 random x,y가 있을 때 x의 조건하에 y일 확률을 말한다.
http://dmml.asu.edu/smm
즉 어떤 x가 주어졌을 때 어떤 클래스에 속할 확률을 구해서 그중 가장 큰 확률을 주는 x가 y라고 보겠다는 것이다.