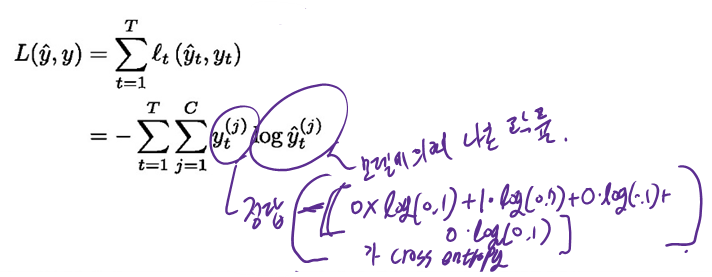해당 글은 https://academy.langchain.com/ 의 Quickstart: LangGraph Essentials 내용을 정리한 것으로, 영상없이 빠르게 내용을 확인하고 싶은 경우에 읽으시면 도움이 됩니다.
Quickstart: LangGraph Essentials
1. LangGraph Orientation
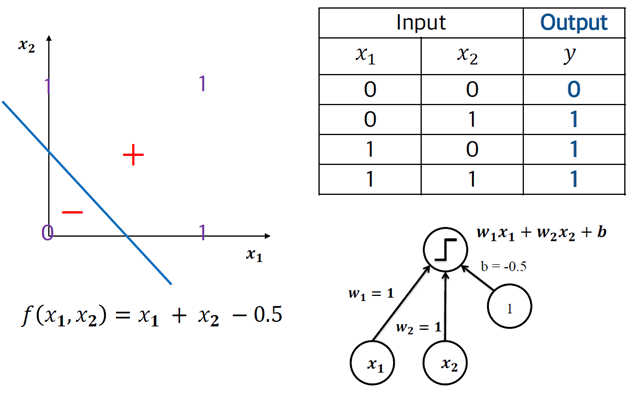
LangGraph란 AI agent와 application을 위한 지속 가능한 런타임을 제공하는 프레임 워크
AI application을 시작하는것은 쉬우나, 이를 맞춤화하고 확장하는 것은 어렵다는 점에서 사용되는 프레임워크
image Gen에서의 ComfyUI와 비슷한 느낌이라 생각하면 된다.
기본 구성 요소:
LLM application에서의 문제점 : 지연시간, 신회성, 응답의 비결정론적 특성
Lang Graph는 다음 방법으로 이 문제점을 해결(사실 해결이라기보단 완화에 가깝다)한다.
- 지연시간
병렬 실행, 스트리밍을 지원
- 신뢰성
체크포인팅 기능.(중단지점부터 실행가능)
- 응답의 가변성
인간의 입력을 기다리는 인간 개입 루프
LangSmith를 통한 추적 및 평가

Lang Graph는 기본 런타임 위에 두개의 사용자 SDK가 있으며, 여기서 StateGraph 가 우리가 흔히 부르는 LangGraph이기도 하다.
이때 LLM, 도구 등의 구성요소는 LangChain 라이브러리에서 제공된다.
LangSmith Deployment에서 호스팅되며, Studio와 LangSmith를 통해 디버깅, 평가, 테스트가 가능하다.
환경설정
academy.langchain.com에서 예시 코드를 수행해볼 수 있다.
JS를 사용하기 위한 방법은 다음과 같다.
먼저 Node.js 20+, Package manager(npm or yarn), OpenAI API key (엔트로픽, langsmith도 있으면 더 좋다)를 준비하고,
demo를 git 클론하고, env에 API key를 넣은 뒤, pnpm으로 의존성을 설치한다(readme 참조)
만약 node.js 20이 깔기 어렵거나, pnpm 명령어가 안먹는다면?
- curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.0/install.sh | bash # nvm 설치
- source ~/.bashrc # 쉘 다시 호출 , ( exec $SHELL 를 사용해도된다)
- nvm install 22 # 원하는 버전으로 설치한다.
- nvm use 22
- nvm alias default 22
- node -v # 기존에 apt install nodejs로 깔린 버전이 있어도, 일단 현제 쉘에서 20+ 나오면 우선 버전이 20+이기에 OK
- corepack enable
- corepack prepare pnpm@latest --activate # pnpm 활성화
- pnpm -v # 숫자나오면 OK
이제 문서상에 있는 실행 예제를 실행한다.
L2 이메일 워크플로
# email processing in Langsmith Studio
pnpm devPython기반을 사용하기위한 방법은 다음과 같다.
python의 경우 기본적으로 conda 환경에 가상환경을 하나 만들어 사용하는 것을 추천하며, Jupyter notebook이나 lab을 사용할 것이기에 환경 생성 후 커널을 추가해준다.
그리고 마찬가지로 git clone 후 .env 파일을 편집해주고, 필요한 패키지를 설치해준다.
Python 환경의 경우 딱히 문제가 생길 소지가 없기에 Readme를 그대로 따라가면 된다.
나의 경우 익숙한 Python 환경에서 수행한다.
ipynb의 경우 md 블록에 설명이 상세하니 해당 부분을 참고해 순서대로 수행해보면 된다.
2. LangGraph foundations
LangGraph의 StateGraph는 5가지의 구성요소가 있다.
- State: Data
- Node: Functions
- Edges: Control Flow
- Serial, Parallel
- Conditional
- Checkpointing/Memory
- Human in the loop : interrupts
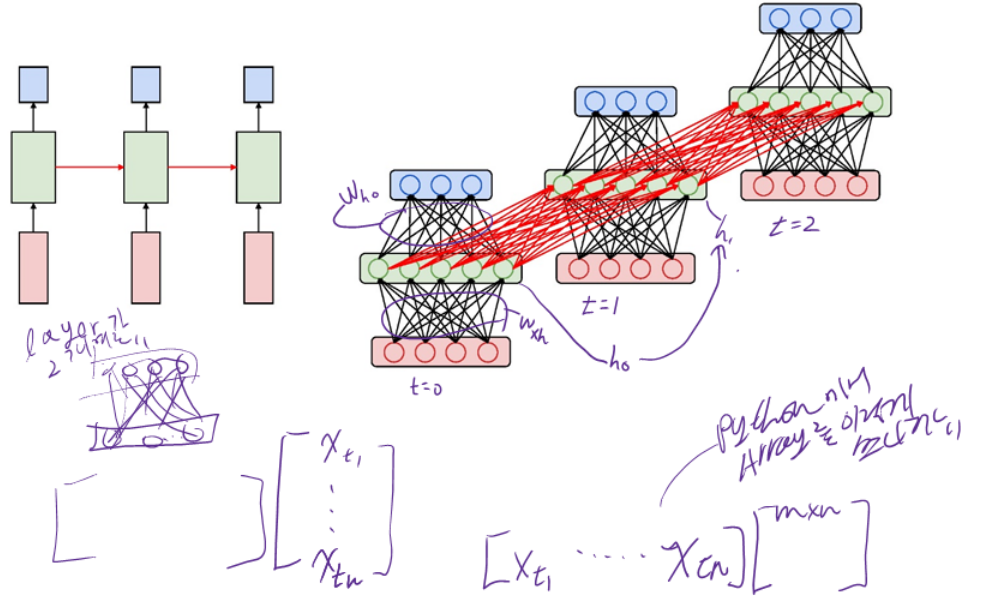
LangGraph를 low level 언어라고 생각해보자, (low level일수록 좀더 기계친화적, 예를들면 어셈블리어는 C보다 lowlevel이고, Python은 high level이다)
State는 Application의 실제 Data이고, Node는 해당 Data를 처리하는 함수이며, Edge는 Application의 제어 흐름을 제공한다. 또한 정적이거나 조건부일 수 있으며, 병렬 또는 직렬로 실행 가능하다.
State는 Checkpointing을 통해 지속될 수 있고, Control Flow는 사용자의 상호작용을 위해 정지를 수행 가능하다.
StateGraph
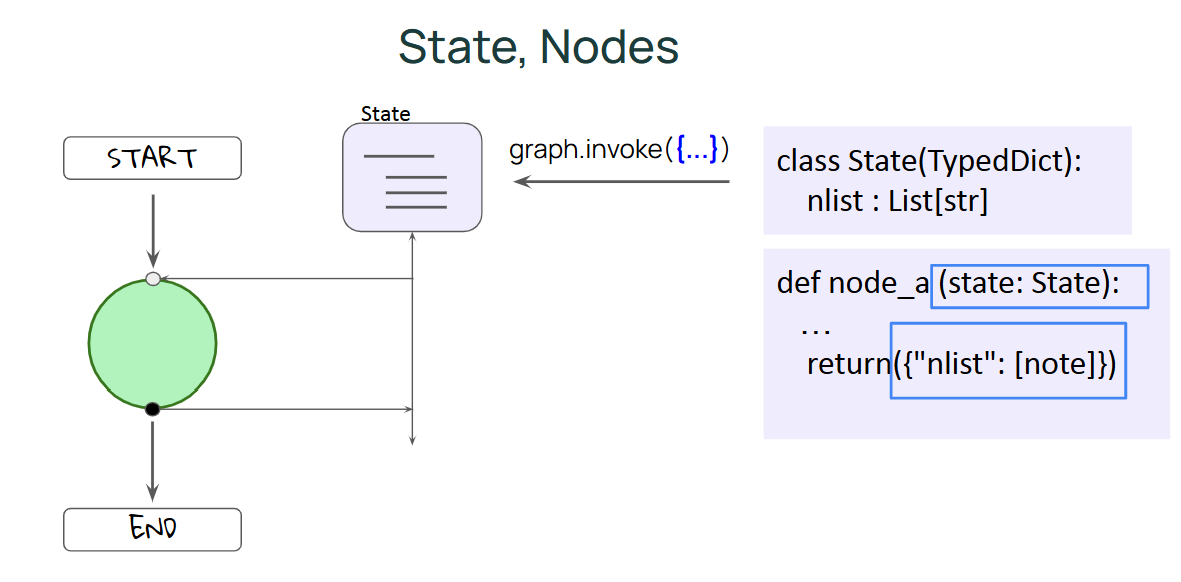
이름과 같이 StateGraph는 State와 그래프를 가지고 있으며, State는 Data이다. 이는 그래프에 적용되고, 그래프에 의해 업데이트되어 사용자에게 반환되며, 그래프 자체는 상태가 없다.
그래프를 정의처럼 다룰수도 있는데, 그래프를 정의할 때는 먼저 그래프가 작동할 상태를 정의하면 이 상태가 그래프의 모든 노드에서 공유된다.
state는 Python 데이터 구조로써, 예제상에서는 단일 필드(문자열 목록)만 있는 타입이 지정된 dict를 사용한다. 따라서 그래프가 호출되면 state가 초기화되고, 그래프 실행 중에 LangGraph 런타임은 실행할 노드를 선택한 다음 현재 상태를 넘겨주고 노드를 실행한 후 최종적으로 state를 업데이트한다.
state 업데이트에는 노드의 결과를 사용하는데, 노드는 함수에 불과하기에 주요 인수는 state고 출력 또한 state에 대한 업데이트이다. (여기서는 문자열 목록에 대한 업데이트) state는 시간의 흐름과 관계없이, 노드에 오류가 발생시에도 유지될 수 있다. 따라서 실행중 노드에 오류 발생시 노드를 다시 시작하고 상태를 복원한 후 함수를 처음부터 다시 실행 가능하다.
이러한 상태 유지를 통한 Application의 복원 탄력성이 langgraph의 핵심 기능중 하나이다(다만 오류 감지를 위해 플렛폼의 지원이 필요).


상태와 노드만 있고, 오른쪽에 단일 노드가 있는 그래프를 만들어보자.
그래프를 만들 떄 가장 먼저 해야할 일은 상태 정의로써 class state를 dict type으로 정의한다. 매개변수는 nlist이고 리스트이며 유형은 문자열이다.(state는 data class가 될수도 있고, Pydantic 기반 모델이 될 수도 있다.)
class State(TypedDict):
nlist: List[str]다음으로 노드를 정의해보면, 노드는 state를 받아서 state에 대한 업데이트를 반환하는 함수이다. 따라서 노드 A를 정의해 state를 받아 state에 대한 업데이트를 반환하고, 그 업데이트가 새 문자열이 되도록 한다.
def noda_a(state: State) -> State:
print(f"node a is receiving {state['nlist']}")
note = "Hello World!"
return(State(nlist = [note]))노드 a에서 Hello world를 반환하고 nlist가 새 문자열을 포함하는 리스트로 설정된 state 리스트를 반환한다. 디버그용 로그를 추가해보면 노드 A는 state['nlist']를 수신한다.
다음으로 그래프를 구축해보자.
bulider = StateGraph(State) # 이를 위해 StateGraph 객체를 상태(state)로 인스턴스화하고, 방금 만든 노드를 추가한다.
bulider.add_node("a", node_a) # 이 노드를 A라고 부르고, 함수 node_a를 추가한 다음,
bulider.add_edge(START, "a") # START에서 A로 가는 간선을 추가한다. 이 경우 Start는 LangGraph에서 가져온 상수이며,
bulider.add_edge("a", END) # 다음으로 A에서 END로 가는 간선을 추가한다.
graph = bulider.compile() # 마지막으로 그래프를 컴파일한다.이제 그래프를 실제로 표시해보자. LangGraph의 draw mermaid 유틸리티를 사용하여 모든 작업이 제대로 완료되었는지 확인할 수 있다.
display(Image(graph.get_graph().draw_mermaid_png())))
#그래프의 그래프 표현을 가져온 다음
# draw_mermaid_png 함수를 호출
이 다이어그램을 직접 생성하는 코드를 얻으려면 draw mermaid 메소드를 호출 할 수도 있다.
print(graph.get_graph().draw_mermaid()) # 결과는 코드로 나오며 이 코드를 웹에 임베드할 수 있다.다시 초기 상태로 그래프를 호출해보자.
initial_state = State( nlist=["Hello Node a, how are you?"]) # 이 초기 상태 변수를 nlist가 있는 상태로 설정
graphinvoke(initial_state) # 이 초기 상태를 사용하여 그래프를 호출
# node a is receiving ['Hello Node a, how are you?']
# {'nlist': ['Hello World']}이제 노드 a가 들어오는 값을 출력하는걸 보면 nlist가 새 메모로 덮어씌워진 것을 볼 수 있다.
핵심은 그래프와 상태를 정의할 때 모든 노드가 동일한 상태를 공유할 수 있다는 것이다. 상태는 타입 딕셔너리, Python 데이터 클래스 또는 Pydantic 기본 모델이 될 수 있고, 노드는 함수일 뿐이라는 것, 그리고 그래프를 실행할 때 LangGraph 런타임이 어떻게 동작하는지를 확인할 수 있다.
Edges

위에서 state와 node를 확인했다면, 또다른 핵심 구성요소는 edge이다. edge는 한 노드에서 다음 노드로 제어를 전달한다.
직렬의 경우, 첫 번째 단계가 끝나면 LangGraph 런타임이 두 번째 노드를 초기화하고 실행하며, 병렬의 경우, 다음 세 노드가 모두 병렬로 실행된다.
여러 단계를 동시에 실행할 수 있기 때문에 노드 간 이러한 단계를 슈퍼 스텝이라고 하며, 더 자세히 살펴보겠지만. 지금은 이 용어를 기억해 두자. 왼쪽 두 예시는 static edge로, 항상 실행된다는 것을 의미하며, 오른쪽 점선으로 표기되는 두 Edge는 은 Conditional Edge이다.
Conditional Edge에지는 조건에 따라 노드에 제어권을 넘겨주는 의사 결정을 가능하게 하기 때문에 매우 유용하다.
Conditional의 경우 , 왼쪽 edge가 선택되도록 해 노드를 실행했고, 오른쪽은 선택되지 않았다. 따라서 오른쪽 노드는 실행되지 않는다.
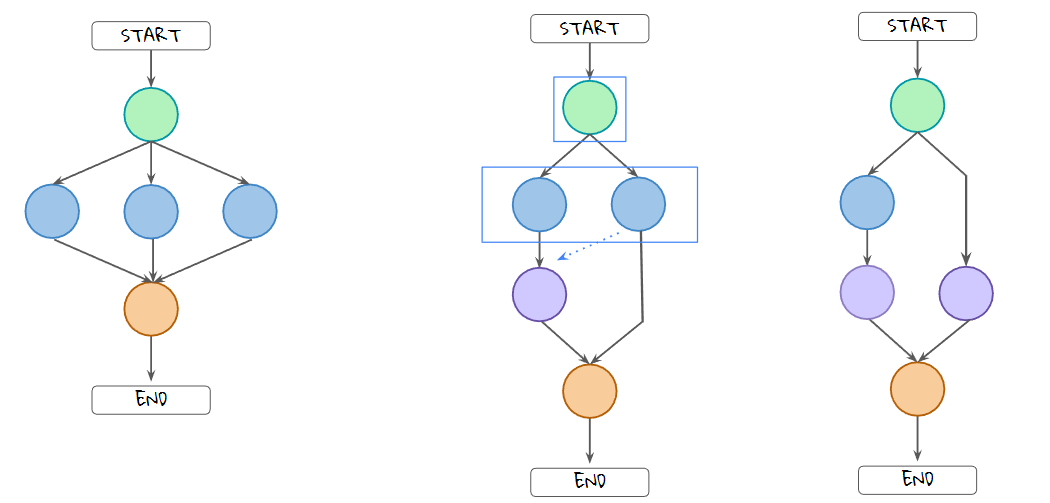
그래프와 같이 모든 활성 노드가 완료되고 값을 state에 저장한 후 다음 노드로 계속 진행하는 것을 슈퍼스탭이라고 한다. 왼쪽 그래프에서 주황색 노드의 입력상태는 파란색 노드의 모든 업데이트 결과이며,
가운대와 같이 경로의 길이가 다른 경우 LangGraph에서는 우측노드의 실행 시점을 지정할 수 있다. 일반적으로 초록 노드 완료시 활성화되고, 보라색 노드의 입력으로 사용될 수도 있으나,
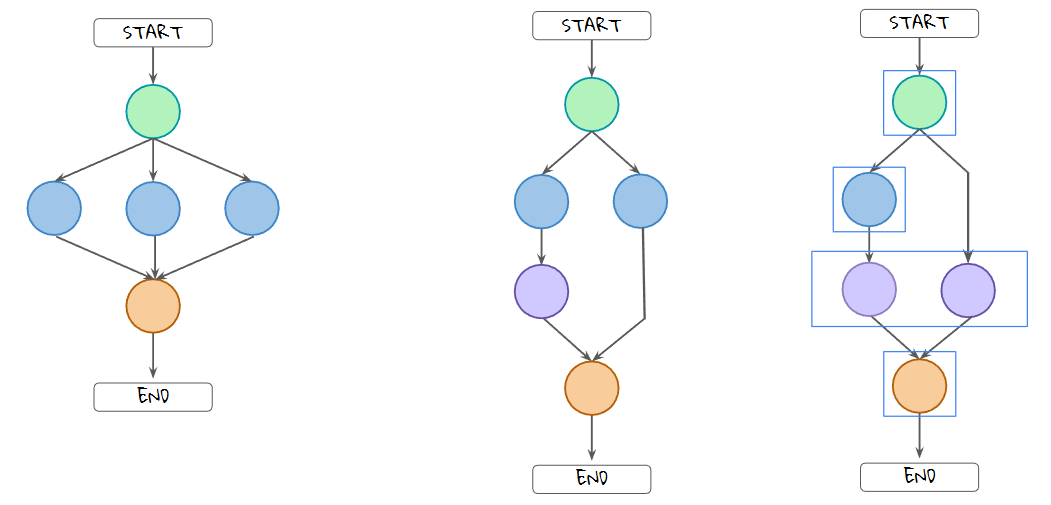
실행을 지연시켜 오른쪽노드의 출력이 보라색 노드와 동일한 슈퍼스텝에서 상태에 추가되도록 할 수도 있다.
병렬 실행과 상태 쓰기에 대해 자세히 살펴보자. 이 단계의 시작 부분에서 노드들은 현재 상태를 제공받고, 실행 후에는 공유 상태를 업데이트한다.

그런데 모든 노드가 상태의 nlist 속성에 대한 업데이트를 반환하면 어떻게 될까?
기본적으로 StateGraph에서 살펴본 바와 같이 마지막에 작성된 값이 이전 상태를 덮어쓴다.

이 문제는 리듀서 함수로 해결 가능하다. 리듀서라는 이름은 일반적인 용어인 MapReduce에서 유래되었으며, 이 함수를 사용하면 동일한 상태 키에 대한 여러번의 기록을 어떻게 처리할지 정의할 수 있다.
노드 실행이 끝날 때 상태 값이 업데이트되면 LangGraph는 해당 키에 대해 제공된 리듀서 함수를 사용하여 상태를 어떻게 업데이트할지 결정할 수 있다.
이 예시에서는 리듀서 함수를 operator dot add로 설정했기 때문에 값이 이전 값을 덮어쓰는 대신 값이 list에 추가된다.
이 리듀서 함수는 직접 정의할 수 있으며, 직접 맞춤형 리듀서를 만들 수도 있다. 이를 위해 state를 정의할 때 state변수를 주석으로 달았으며, 구문은 이미지와 같다. 첫번째 인수는 type, 두번째 reducer function은 메타데이터이며, LangGraph는 이를 사용해 리듀서 동작을 지정한다.


edge와 병렬 실행에 대해 알아보자.
이 다이어그램은 세 개의 노드가 모두 병렬로 실행되는 다이어그램이다. 지금 만들 그래프도 바로 이 그래프로,
보라색 추가 노드에 대해서는 두 개의 서로 다른 분기가 있으며, 노드의 병렬 실행 또한 같이 살펴본다. 이러한 상황에서 상태 업데이트가 왜, 그리고 어떻게 발생하는지 이해해보자.
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
# 먼저 필요한 모듈을 임포트
class State(TypedDict):
nlist: Annotated[List[str], operator.add]
# 이전에 정의했던 것과 동일한 상태를 다시 생성, nlist는 문자열 목록이고, 이번에는 리듀서를 도입.
# reducer 함수로 operator.add를 사용하면, 이전 값을 덮어쓰지 않고 모든 리스트 업데이트를 상태에 연결 가능.
def node_a(state: State) -> State:
print(f"Adding 'A' to {state['nlist']}")
return(State(nlist = ["A"]))
def node_b(state: State) -> State:
print(f"Adding 'B' to {state['nlist']}")
return(State(nlist = ["B"]))
def node_c(state: State) -> State:
print(f"Adding 'C' to {state['nlist']}")
return(State(nlist = ["C"]))
def node_bb(state: State) -> State:
print(f"Adding 'BB' to {state['nlist']}")
return(State(nlist = ["BB"]))
def node_cc(state: State) -> State:
print(f"Adding 'CC' to {state['nlist']}")
return(State(nlist = ["CC"]))
def node_d(state: State) -> State:
print(f"Adding 'D' to {state['nlist']}")
return(State(nlist = ["D"]))
# 노드를 정의한다.
# 각 노드는 상태를 받아서 자신의 이름, 입력값을 출력한 뒤
# 자신의 label을 nlist에 대한 업데이트로 반환.
# 그래프를 만들자.
builder = StateGraph(State)
# 먼저 stategraph를 state와 함께 인스턴스화.
# Add nodes
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
builder.add_node("bb", node_bb)
builder.add_node("cc", node_cc)
builder.add_node("d", node_d)
# 위에서 정의한 노드를 추가
# Add edges
builder.add_edge(START,"a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "bb")
builder.add_edge("c", "cc")
builder.add_edge("bb", "d")
builder.add_edge("cc", "d")
builder.add_edge("d",END)
# Start->A, A-B, A-C, B-BB, C-CC, BB-D, CC-D, D-END로 edge를 추가
# Compile and display
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
# 마지막으로 그래프를 컴파일한 뒤 Draw Mermaid 함수로 표시하면
# 위의 보래색과 동일한 그래프가 생성. 이제 실행해보면
initial_state = State(
nlist = ["Initial String:"]
)
# 그래프를 호출하는 초기 상태는 단일 문자열이 포함된 리스트로 제공한다.
graph.invoke(initial_state)
# 그럼 다음과 같은 결과가 나온다.
# Adding 'A' to ['Initial String:']
# Adding 'B' to ['Initial String:', 'A']
# Adding 'C' to ['Initial String:', 'A']
# Adding 'BB' to ['Initial String:', 'A', 'B', 'C']
# Adding 'CC' to ['Initial String:', 'A', 'B', 'C']
# Adding 'D' to ['Initial String:', 'A', 'B', 'C', 'BB', 'CC']
# {'nlist': ['Initial String:', 'A', 'B', 'C', 'BB', 'CC', 'D']}먼저, 노드 A가 실행되고 A를 추가한다. 노드 A가 실행될 때 관찰한 유일한 상태는 그래프를 호출할 때 전달한 초기 상태이며 다른 노드들은 아직 레이블을 추가하지 않은 상태이다.이는 실행 순서에서 A가 첫 번째이기 때문이며,
노드 C와 B는 같은 슈퍼 스텝 내에서 실행된다.
둘 다 실행 시 동일한 상태라는것을 확인 가능한데, 이는 둘중 하나가 다른것보다 먼저 실행되거나 늦게 실행될 수 없다는 것을 의미한다.
이제 BB가 실행되고 CC가 다음 슈퍼 스텝을 실행한다. 이때 두 노드 모두 노드 B와 C의 상태 업데이트를 볼 수 있다는 것을 알 수 있다. 여기서 주의해야 할 점이 이 동작이 LangGraph의 중요한 기능을 강조한다는 점으로, Edge는 제어 흐름을 정의하지만, 노드가 접근할 수 있는 데이터를 제어하지는 않는다는 것이다. 따라서 노드가 실행되면 “병렬 분기에서 작성된 값을 포함한 “현재 그래프 상태에 접근할 수 있는 것이다.
다시 말해, BB는 노드 B뿐만 아니라 노드 C의 상태 업데이트에도 접근할 수 있고, 마찬가지로 CC는 노드 B와 노드 C의 상태 업데이트에도 접근할 수 있다. 두 경우 모두 노드 A에도 접근할 수 있다. 그렇기에 노드 BB와 CC가 state에 자신의 레이블을 추가하는 것을 볼 수 있다.
그리고 D가 실행되면 이전의 모든 추가된 상태를 수신하고 D를 추가한다.
마지막으로 그래프는 모든 노드의 레이블을 포함하는 최종 병합 상태 목록을 반환한다.
그럼 핵심은 무엇인가?
- 상태를 설정할 때, 상태 정의에서 리듀서 함수를 사용하여 상태가 어떻게 누적될지 변경할 수 있으며,
- 그래프를 작성할 때 'add edge'를 사용하여 병렬 경로를 생성할 수 있다.
- 실행 중 노드 B와 C는 병렬로 실행된다. 그래프는 리듀서 함수를 사용하여 각 노드에서 반환된 값을 병합한 다음, 노드 B와 C의 결과를 노드 BB와 CC를 시작하기 전에 상태에 저장한다. 이때, 제어는 에지를 따르지만, 데이터는 그렇지 않다.
Conditional Edges

이번에는 Conditional 즉 조건부 edge에 대해 확인해보자.
그림에 나와있는 (왼쪽)다이어그램상 조건에 따라 왼쪽 또는 오른쪽으로 분기되는 조건부 edge가 있다. 이번에는 이 그래프를 생성해보자. 점선은 Conditional 조건부이며, 실선은 static 정적 edge이다.
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
# 필요한 모듈을 가져온뒤
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
# state는 지난번과 동일하게, 주석이 달린 구문을 사용하여 상태 업데이트를 누적하고, 이전의 내용을 덮어쓰지 않는다.
# 이전 코드에서는 노드간의 정적 간선을 정의했으나, 이번에는 그래프가 동적으로 어떤 간선을 선택할지 결정한다.
def node_a(state: State) -> Command[Literal["b", "c", END]]:
select = state["nlist"][-1]
if select == "b":
next_node = "b"
elif select == "c":
next_node = "c"
elif select == "q":
next_node = END
else:
next_node = END
return Command(
update = State(nlist = [select]),
goto = [next_node]
)
def node_a(state: State):
return
def node_b(state: State) -> State:
return(State(nlist = ["B"]))
def node_c(state: State) -> State:
return(State(nlist = ["C"]))
# 노드 a, 노드 b, 노드 c라는 세 개의 노드를 정의한다.
# 노드 a는 반환만 하고 상태를 업데이트하지 않는다.
# 노드 b는 상태에 레이블을 추가하고,
# 노드 c도 상태에 레이블을 추가한다.
# 이제 그래프를 만들자.
builder = StateGraph(State)
# stategraph를 state와 함께 인스턴트화 한 뒤
# 노드를 만들고
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
# 시작에서 a, a에서 end, c에서 end로 가는 간선을 추가한다.
builder.add_edge(START, "a")
builder.add_edge("b", END)
builder.add_edge("c", END)
# 마지막으로 Draw Mermaid 함수로 그래프를 컴파일하고 표시하면
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))

그래프 모양이 좀 이상한 이유는 b 노드와 c노드에 늘어오거나 나가는 정적 간선을 정의하지 않았기 때문인데, 정의하지 않은 이유는 a에서 end로, a에서 b로, a에서 c로 가는 조건부 간선이 있기를 원하기 때문이다.
이를 상태를 받아들이고 다음으로 분기할 노드를 문자열로 반환하는 조건부 간선 함수로 정의할 수 있다.
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
def node_a(state: State):
return
def node_b(state: State) -> State:
return(State(nlist = ["B"]))
def node_c(state: State) -> State:
return(State(nlist = ["C"]))
###########이제 조건부 간선을 추가하면
def conditional_edge(state: State) -> Literal["b", "c", END]:
select = state["nlist"][-1]
if select == "b":
return "b"
elif select == "c":
return "c"
elif select == "q":
return END
else:
return END
# 그래프 상태를 받아들이고 b,c 또는 end라는 Litreal을 반환하는 조건부 간선을 정의한다.
# end는 LangGraph에서 가져온 예약된 노드 레이블이다.
# 이 조건부 간선 함수는 단순히 state에 마지막으로 기족된 값을 가져오기에
# b였다면 노드 b로 분기하고, c였다면 c, q였다면 end로 분기한다.
# 그렇지 않은 예외 발생시 끝으로 돌아간다.
builder = StateGraph(State)
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
# 이제 조건부 간선을 추가하는 구문으로 그래프에 조건부 간선을 추가한다.
builder.add_conditional_edges("a", conditional_edge)
builder.add_edge(START, "a")
builder.add_edge("b", END)
builder.add_edge("c", END)
# 마지막으로 Draw Mermaid 함수로 그래프를 컴파일하고 표시하면
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png())) 
원하던 형태의 조건부 간선이 그려진다.
이제 사용자로부터 입력을 받아 이 입력으로 입력 state를 생성하고 해당 state로 그래프를 호출해보자
user = input('b, c, or q to quit: ')
input_state = State(
nlist = [user]
)
graph.invoke(input_state)
# b, c, or q to quit:
# {'nlist': ['', '']}
# {'nlist': ['b', 'B']} 입력에 맞게 노드로 이동하는 것을 확인할 수 있다.
# {'nlist': ['c', 'C']}
# {'nlist': ['q']}다음으로 LangGraph의 내장함수로 조건부 분기를 구성해보자
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
# 동적 간선 함수 대신 노드 a가 다음에 방문할 노드를 선택하게 하려면 노드 a를 수정한다.
# def node_a(state: State):
# return
# 대신 다음과 같이 하면 선택 로직이 노드 a에 포함된다.
def node_a(state: State) -> Command[Literal["b", "c", END]]: # 그래프 상태를 수신하고, 상태에 마지막으로 기록된 값을 기준으로 선택한다.
# 이때 함수가 명령을 반환할 것이라 명시했고, 그에따라 B,C,END중 하나를 반환한다.
# 이런 반환 유형 주석은 그래프 작동에 실제로 영향을 주진 않지만
# 그래프 그림이 정확히 만들어질 수 있게 해준다
# 만약 -> Command[Literal["b", "c", END]]부분을 제거하면
# 동작은 동일할지라도 그래프 이미지는 다시 이전처럼 이상한 모양이 나온다
select = state["nlist"][-1]
if select == "b": # 값이 B이면 노드 B로, 값이 C이면 노드 C로, 값이 Q이면 노드 End로 이동하고, 이외의 값이면 노드 End로 이동한다.
next_node = "b"
elif select == "c":
next_node = "c"
elif select == "q":
next_node = END
else:
next_node = END
# return에서 달라진 부분은 상태를 업데이트하기 위해 단순히 값을 반환하는 대신 명령을 반환한다.
return Command(
update = State(nlist = [select]), # 명령어를 사용해 이전과 같이 상태를 업데이트한다 (마지막 값을 복제)
goto = next_node # 그래프가 이동할 다음 노드를 지정한다.
# 유의할 점은 goto에 지정된 값은 런타임중에만 확인되기에, 이 문자열을 노드의 이름과 일치시켜야만
# 또한 goto가 노드 목록일 수도 있다는 점을 유용히 사용하자.
# 즉, goto = [next_node]여도 동일하게 동작한다.
)
**def node_b(state: State) -> State:**
return(State(nlist = ["B"]))
def node_c(state: State) -> State:
return(State(nlist = ["C"]))
def conditional_edge(state: State) -> Literal["b", "c", END]:
select = state["nlist"][-1]
if select == "b":
return "b"
elif select == "c":
return "c"
elif select == "q":
return END
else:
return END
builder = StateGraph(State)
# Add nodes
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
# Add edges
builder.add_edge(START, "a")
builder.add_edge("b", END)
builder.add_edge("c", END)
# builder.add_conditional_edges("a", conditional_edge) 이제 이 줄을 제거해도
# 위 코드와 같이 간선이 제대로 랜더링된다.
# Compile and display
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
# 이제 기능이 잘 작동하는지 확인을 위해 반복마다 사용자 입력을 받게 해보자.
while True:
user = input('b, c, or q to quit: ')
print(user)
input_state = State(nlist = [user])
result = graph.invoke(input_state)
print( result )
if result['nlist'][-1] == "q":
print("quit")
break
# b
# {'nlist': ['b', 'b', 'B']}
# c
# {'nlist': ['c', 'c', 'C']}
# q
# {'nlist': ['q', 'q']}
# quit이상으로
- 그래프를 만들 때 그래프 상태를 받아서 다음 노드를 결정하는 조건부 간선 함수를 사용하여 조건부 간선을 추가할 수 있다는것.
- 또한 nodes의 반환문에 명령을 사용하여 update로 그래프 상태를 업데이트하고 goto로 제어 경로를 업데이트할 수도 있다는 것
을 확인했고, 두 방법 모두 유효하다
Memory/ Checkpointers
다음으로, 체크포인터를 사용하여 그래프에 메모리를 추가하여 장기 지속성을 구현하는 방법에 대해 확인해보자.
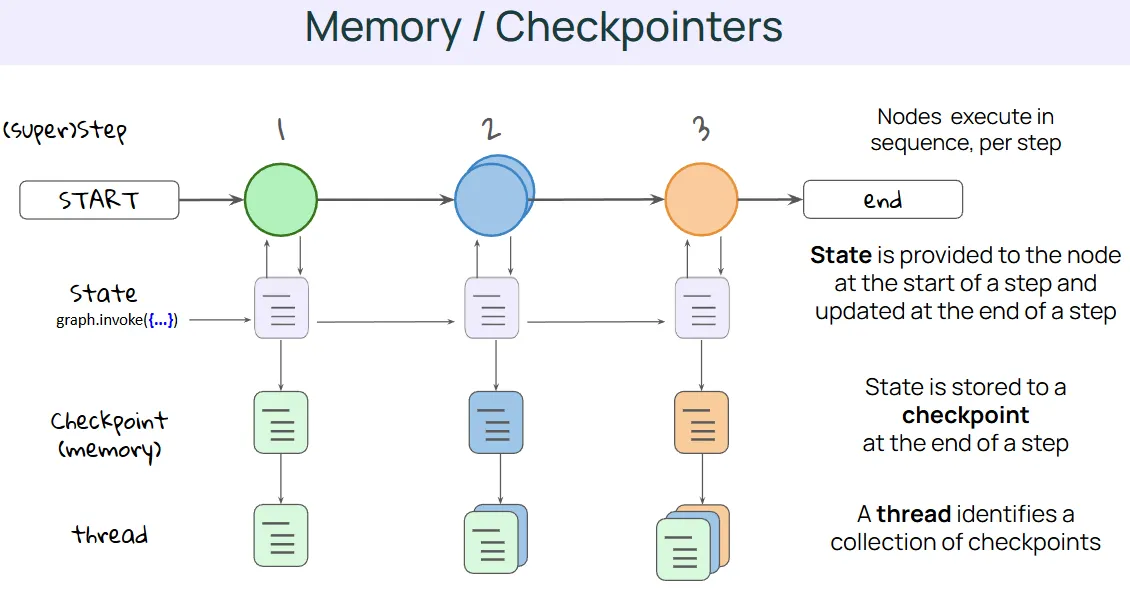
여지것 노드들이 순차적으로 실행되는 것을 확인했고, 특정 단계에서는 병렬로 실행될 수도 있으며, 이러한 과정을 Super Step이라 부른다는 것을 확인했다. 상태는 그래프 전체에서 공유되며, 슈퍼 스텝 시작 시 노드에 제공되고, 슈퍼 스텝 종료 시 해당 노드에 의해 업데이트 된다.
다음으로 실행간 그래프 상태를 유지하기 위한 지속성 개념을 확인해보자.
체크포인터를 사용하여 메모리를 할당할 수 있다. 체크포인터는 각 단계가 끝날 때 상태를 지속성을 가지는 저장소에 저장하는데, 이는 쉽게말해 해당 시점의 상태 스냅샷을 찍는 것과 동일하다.
스레드는 시간 경과에 따라 모인 이러한 체크포인트들의 집합으로, 각 실행 단계의 상태에 대한 전체 이력을 나다낸다. 체크 포인트 사용시의 이점은 다음과 같다.

- 노드가 실패하더라도 상태를 복원하고 진행상황을 지속하며 다시 작업 수행이 가능
- 이전 시점의 상태를 복원할 수 있음. 예를들어 실행시간이 긴 agent가 길을 잃었다 하더라도 문제없이 필요한 시점. 즉 정상적으로 작동하기까지의 시점을 다시 복원 가능하다
- 체크포인팅을 사용시 지속적으로 상태를 유지할 수 있고, 이는 그래프가 “실행중이 아닐 때에도” 상태가 유지된다.
- 어느 단계에서든 상태를 복원할 수 있다. 즉, 노드가 중단되어도 중단했던 위치부터 바로 실행이 가능하다.(이 부분은 추후 다룰Interrupt/HIL(Human In The Loop)에서 좀더 상세히 다룬다)
이제 그래프에 메모리를 추가해보자
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
def node_a(state: State) -> Command[Literal["b", "c", END]]:
select = state["nlist"][-1]
if select == "b":
next_node = "b"
elif select == "c":
next_node = "c"
elif select == "q":
next_node = END
else:
next_node = END
return Command(
update = State(nlist = [select]),
goto = next_node
)
**def node_b(state: State) -> State:**
return(State(nlist = ["B"]))
def node_c(state: State) -> State:
return(State(nlist = ["C"]))
def conditional_edge(state: State) -> Literal["b", "c", END]:
select = state["nlist"][-1]
if select == "b":
return "b"
elif select == "c":
return "c"
elif select == "q":
return END
else:
return END
builder = StateGraph(State)
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
builder.add_edge(START, "a")
builder.add_edge("b", END)
builder.add_edge("c", END)
graph = builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
# 위 부분까진 동일하며, 이제 이 조건부 간선 그래프에 체크포인트를 추가해 상태를 지속시킨다.
# LangGraph는 기본적으로 세 가지 체크포인트 구현을 제공한다.
# 체크포인트 정보를 메모리에 저장하는 인메모리 세이버(in-Memory Saver),
# 체크포인트를 해당 데이터베이스에 저장하는 Postgres 세이버(Postgres Saver) ,
# SQL 라이트 세이버(SQL Light Saver)가 있다.
# 여기서는 설정이 가장 간단한 인메모리 세이버를 사용한다.
from langgraph.checkpoint.memory import InMemorySaver
memory = InMemorySaver() # LangGraph 체크포인트 메모리에서 임포트한 후 인스턴스화하고 스레드 ID를 구성.
config = {"configurable": {"thread_id": "1"}} # 이 커스텀 가능한 키가 있는 dict 구조가 실제로 그래프에 구성을 전달하는 방법이다.
# 일단 임의의 스레드 id로 1을 주고
graph = builder.compile(checkpointer=memory)
# 실행하면 그래프에 메모리가 생기기에, 실행해보면
while True:
user = input('b, c, or q to quit: ')
input_state = State(nlist = [user])
result = graph.invoke(input_state, config )
print( result )
if result['nlist'][-1] == "q":
print("quit")
break
# b
# {'nlist': ['b', 'b', 'B']}
# c
# {'nlist': ['b', 'b', 'B','c', 'c', 'C']}
# q
# {'nlist': ['b', 'b', 'B','c', 'c', 'C','q', 'q']}
# quit
# 위와 같이 반복 루프에서 상태가 계속 누적되는 것을 확인할 수 있다.여기서 기억할 부분은
- 메모리를 설정할 때 체크포인터를 인스턴스화하는데, 여기서는 메모리 내 저장 기능을 사용했지만, 다양한 옵션이 있다. (memory = InMemorySaver() )
- 그래프를 작성할 때 해당 체크포인터를 사용하여 그래프를 컴파일한다. (graph = builder.compile(checkpointer=memory))
- 그래프 실행 중에는 구성 변수에 설정한 스레드 ID로 그래프를 호출한다. 동일한 스레드 ID를 사용하는 경우 그래프 실행간에 상태가 유지된다 (config = {"configurable": {"thread_id": "1"}})
Human In the Loop: Interrupt
다음으로 인터럽트에 대해 알아보고, 루프 내에서 HIL을 어떻게 구현할 수 있는지 알아보자.
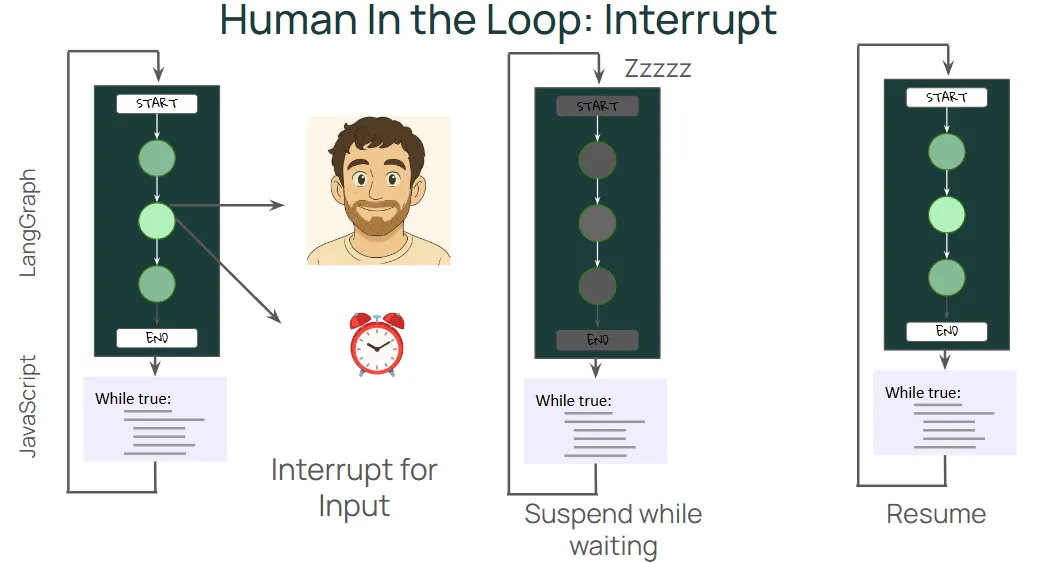
지금까지 한 내용에서 그래프를 호출하고 실행하는 루프가 있고. 이 루프는 Python 런타임으로 돌아와서 반복된다. 방금까지 실행한 코드는 런타임 중에 사용자 입력을 수집했다.
하지만 경우에 따라 그래프가 외부 입력을 읽어야 하는 경우가 있는데, 예를 들어 도구를 실행하거나 데이터베이스에 쓰기 전에 사람의 승인을 받아야 하는 경우가 있다. 사람의 응답에는 시간이 걸릴 수 있으므로, 대기하는 동안 작업을 일시 중지했다가 정보가 제공되면 다시 시작하는 것이 이상적이며, 이러한 경우에 인터럽트가 사용된다.
인터럽트는 대기하는 동안 작업을 일시 중지하고 그래프를 대기 상태로 둔 다음, 다시 시작하면 작업을 Resume한다.
이 저장 및 복원 작업은 체크포인터 덕분에 가능하며, 이를 확인해보면 (Interrupt는 가장 중요한 기능으로 강조되므로, 유의깊게 생각하며 확인할 것)
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
# 직전까지 살펴본 그래프를 사용할 것이기에, 필요한 모듈 import
from langgraph.checkpoint.memory import InMemorySaver
memory = InMemorySaver()
config = {"configurable": {"thread_id": "1"}}
# 이전과 동일한 체크포인트
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
# 동일한 state 사용하며
def node_a(state: State) -> Command[Literal["b", "c", END]]:
# 여기서 차이가 발생. 노드 B와 노드 C는 같은 방식으로 정의되어 있지만, 노드 a의 정의는 약간 다르다.
print("Entered 'a' node") # # 노드 A가 실행될 때마다 명확하게 알 수 있도록 노드 시작 부분에 print 문을 추가. 이는 단순히 디버깅을 위한 것임.
select = state["nlist"][-1]
if select == "b":
next_node = "b"
elif select == "c":
next_node = "c"
elif select == "q":
next_node = END
# 조건 분기 논리는 대부분 동일하게 유지된다.
# nlist의 마지막 요소를 기준으로 분기한다.
# B이면 노드 B로, C이면 노드 C로, Q이면 노드 끝으로 이동하는데,
else: # illegal value
# 여기서 차이점은 이전에는 catch all을 사용하면 종료되지만, 이제는 잘못된 값의 경우 인터럽트를 발생시킬 것이다. 인터럽트 함수는 LangGraph.types에서 가져온다.
admin = interrupt(f"Unexpected input '{select}'")
# 이 함수의 경우 이 코드 줄을 만나면 그래프가 중단되고 예상치 못한 입력 메시지와 잘못된 값을 반환한다. 그래프를 다시 시작할 때, 결과는 이 admin 변수에 저장되고, 출력된다.
print(admin)
if admin == "continue": # 만약 해당 resume 값이 continue이면, 다음으로 이동할 노드는 B가 된다.
next_node = "b"
else: # 그렇지 않으면 바로 end로 이동한다.
next_node = END
select = "q"
return Command(
update = State(nlist = [select]),
goto = next_node
# 그리고 이전과 동일하게 상태를 업데이트하고, 다음 노드로 이동하는 명령을 반환한다.
)
def node_b (state: State) -> State:
return(State(nlist = ["B"]))
def node_c (state: State) -> State:
return(State(nlist = ["C"]))
builder = StateGraph(State)
# 이제 동일하게 그래프를 구성하자. 노드 A, B, C를 추가하고, 간선을 추가한 후, 앞서 정의한 체크포인터로 컴파일한다.
# Add nodes
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
# Add edges
builder.add_edge(START,"a")
builder.add_edge("b", END)
builder.add_edge("c", END)
# Compile
graph = builder.compile(checkpointer=memory)
# 이제 이전에 사용한 루프를 사용해보자. 사용자 입력을 받아서 그래프에 전달하는 루프이기에, 따라서 잘못된 입력으로 이 그래프를 호출하면 해당 인터럽트 명령문이 실행된다.
while True:
user = input('b, c, or q to quit: ')
input_state = State(nlist = [user])
result = graph.invoke(input_state, config)
print(result)
break; # 결과를 출력하고, 인위적인 중단점을 추가해본다.
if result['nlist'][-1] == "q":
print("quit")
break
# 이제 실행하고 잘못된 값을 입력해보면
# Entered 'a' node
# {'nlist': ['b', 'b', 'B', 'a', 'kkk'], '__interrupt__': [Interrupt(value="Unexpected input 'kkk'", id='8d56bc2138dfjka92d0c594f8f39')]}
결과에 실행된 값을 확인해보면, a 노드에 진입했지만 잘못된 값이 입력되었고, 그래프가 제공한 결과에 인터럽트 키가 포함되어 있는 것을 확인할 수 있다. 이 키는 발생한 인터럽트를 포함하는 목록을 저장하며, 값은 발생한 메시지이다. 그리고 ID가 할당되어있는 것을 볼 수 있다.
이제 해야할 일은 이런 인터럽트를 처리하는 방법을 그래프에 알려주는 것으로, 기본적인 인터럽트 핸들러 구현을 통해 수행 가능하다.
from IPython.display import Image, display
import operator
from typing import Annotated, List, Literal, TypedDict
from langgraph.graph import END, START, StateGraph
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import InMemorySaver
memory = InMemorySaver()
config = {"configurable": {"thread_id": "1"}}
class State(TypedDict):
nlist : Annotated[list[str], operator.add]
def node_a(state: State) -> Command[Literal["b", "c", END]]:
print("Entered 'a' node")
select = state["nlist"][-1]
if select == "b":
next_node = "b"
elif select == "c":
next_node = "c"
elif select == "q":
next_node = END
else: # illegal value
admin = interrupt(f"Unexpected input '{select}'")
print(admin)
if admin == "continue":
next_node = "b"
else:
next_node = END
select = "q"
return Command(
update = State(nlist = [select]),
goto = next_node
)
def node_b (state: State) -> State:
return(State(nlist = ["B"]))
def node_c (state: State) -> State:
return(State(nlist = ["C"]))
builder = StateGraph(State)
builder.add_node("a", node_a)
builder.add_node("b", node_b)
builder.add_node("c", node_c)
builder.add_edge(START,"a")
builder.add_edge("b", END)
builder.add_edge("c", END)
graph = builder.compile(checkpointer=memory)
while True:
user = input('b, c, or q to quit: ')
input_state = State(nlist = [user])
result = graph.invoke(input_state, config)
# break를 제거하고
if '__interrupt__' in result:
print(f"Interrupt:{result}") # 인터럽트의 메시지를 출력한다.
msg = result['__interrupt__'][-1].value
print(msg) # 그리고 사람에게 입력을 요청한다.
human = input(f"\n{msg}: ")
human_response = Command(
resume = human # 그리고 해당 입력을 이용해 사용자 응답을 구성한다. 이 경우 재개 속성을 제공시킨다.
)
result = graph.invoke(human_response, config) # 마지막으로 인간의 응답과 이전의 설정을 사용해 그래프를 호출한다.
# 유의할 점은 그래프가 메모리를 가지려면 이전 실행에서 상태를 복원하려는 동일한 스레드 id로 호출되어야 한다는 점이다.
if result['nlist'][-1] == "q":
print("quit")
break
# 이제 실행해보면..
# b, c, or q to quit: kkk
# Entered 'a' node
# Interrupt:{'nlist': ['b', 'b', 'B', 'a', 'kkk', 'kkk'], '__interrupt__': [Interrupt(value="Unexpected input 'kkk'", id='1db86e128r9e82j39fj4387c6fb7')]}
# Unexpected input 'kkk'
# Unexpected input 'kkk': continue
# Entered 'a' node
# continue
# b, c, or q to quit: b
# Entered 'a' node
# b, c, or q to quit: q
# Entered 'a' node
# quit출력을 확인해보면, 노드에 진입 후 인터럽트가 발생했고, 인터럽트 메시지가 나타난다. 그리고 입력하라는 메시지가 표시되었으,. continue를 입력하면 재개된 후 continue를 입력하고 B로 이동한다. 그러면 continue를 입력하고 노드 B로 이동한 것을 볼 수 있는데, 지금 보면, . "Entered a node"를 다시 출력하는 것을 볼 수 있다.
즉, 처음부터 재실행됬다는 것인데, 그 이유는 노드의 크기가 클 수 있기 때문이다.
따라서 인터럽트 발생 시에는 노드를 오프라인 상태로 전환해야 하며, 만약 노드 중간에서 재개했다면 모든 중간 상태는 유지되어야 할 것이다. 따라서 인터럽트는 노드 시작 부분부터 다시 실행되기에 이런 응답이 나오는 것이다.
인터럽트가 계속 발생하는 경우, LangGraph는 자동으로 응답을 체크포인트하고,
이미 발생한 인터럽트를 발견하면 해당 응답을 제공하며, 여러 인터럽트를 연속으로 발생시켜도 LangGraph가 현재 어떤 인터럽트에 있는지 추적할 수 있다.
'interrupt': [Interrupt(value="Unexpected input 'kkk'", id='1db86e128r9e82j39fj4387c6fb7')]를 보면 값이 리스트로 구성되어 있는데, 그 이유는 그래프가 여러 인터럽트를 발생시킬 수 있기 때문이다. 예를 들어, 병렬로 실행 중인 두 노드가 모두 인터럽트를 발생시키면 이 리스트에는 두 인터럽트가 모두 포함된다.
여기까지 노드 로직에 인터럽트 문을 추가했고, 이를 처리하기 위해 인터럽트 핸들러를 추가했다.
기억할 점은 다음과 같다.
- 실행 중에 인터럽트가 발생하면 작업이 일시 중지되고 그래프가 인터럽트 필드에 값을 반환하는 방식을 살펴보았고, 재개를 포함하는 명령으로 그래프가 호출되면 그래프에 값이 반환되고 작업이 계속되는것,
- 그리고 노드가 처음부터 다시 시작되는 것을 확인했다. 이것은 체크포인터가 인터럽트에 대한 응답을 재생하기 때문이다.
'IT > 뻘짓' 카테고리의 다른 글
| http에서 https로 변경 + 체크해볼 부분 (0) | 2025.11.03 |
|---|---|
| Ubuntu GPU 추가 (0) | 2025.11.02 |
| Windows server 2016 Hyper-v gpu 할당 (0) | 2024.10.21 |
| be700-kr 호환 배터리 (0) | 2022.08.09 |