Chpter05 Sequence-to-Sequence with Attention
5.1 Seq2seq:Encoder-DecoderModel

5.1.1 Seq2seq : Encoder
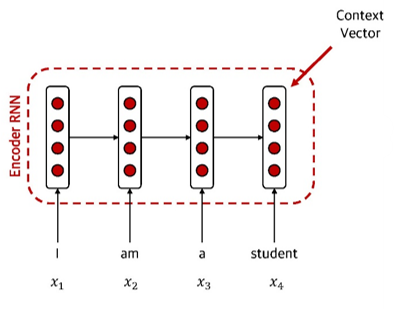
input token $x_1, \ldots, x_T$ 에 대하여
Context vector C 는 T시점에서의 RNN 의 hidden state, 즉 $h_T$
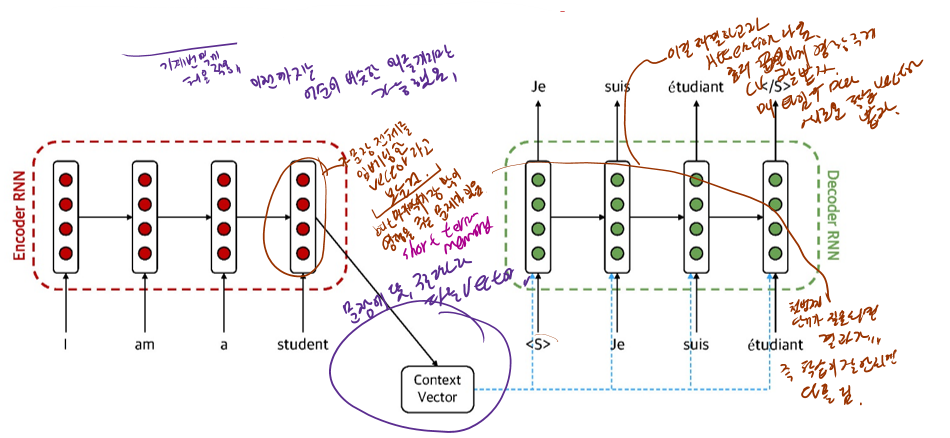
5.1.2 Seq2seq : Decoder

5.1.2 Seq2seq : Decoder (Cho et al.)
5.1.3 Seq2seq : Encoder-Decoder Graph Repressentation
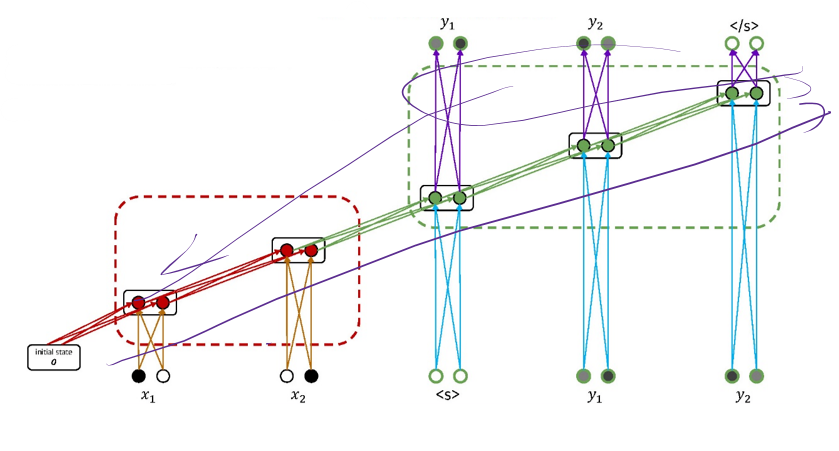
5.1.3 Seq2seq : Encoder-Decoder Model Training

5.1.4 Seq2seq : Encoder-Decoder Model for ASR

5.2 Seq2Seq: The Bottleneck Problem

5.2.1 Attention
- Bottleneck problem에 대한 해결을 위해 attention 개념이 제안됨
- Core idea : 각 시점마다 decoder에서 입력 sequence의 특정 부분에 초점을 맞출 수 있도록 encoder로 직접적으로 연결
5.2.2 Seq2Seq with Attention

5.2.2 Seq2Seq with Attention
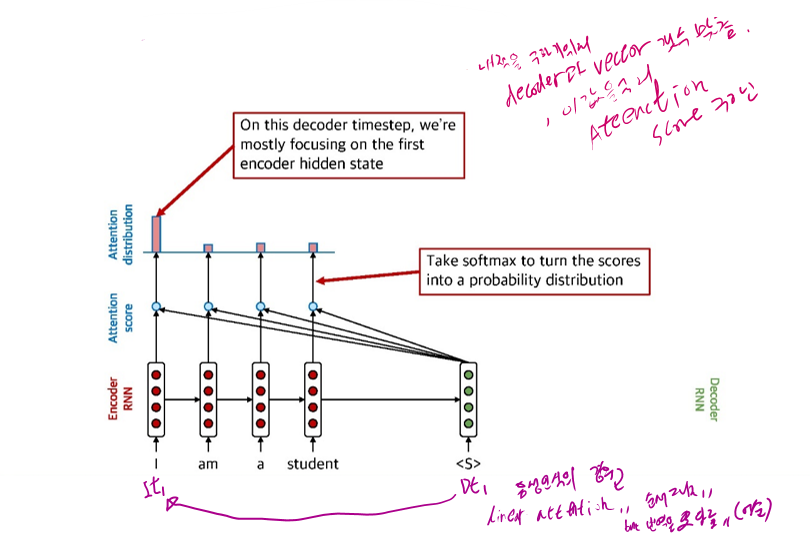
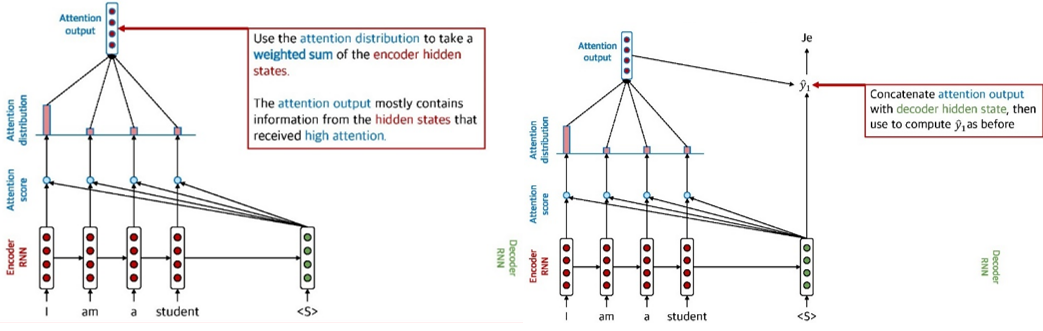

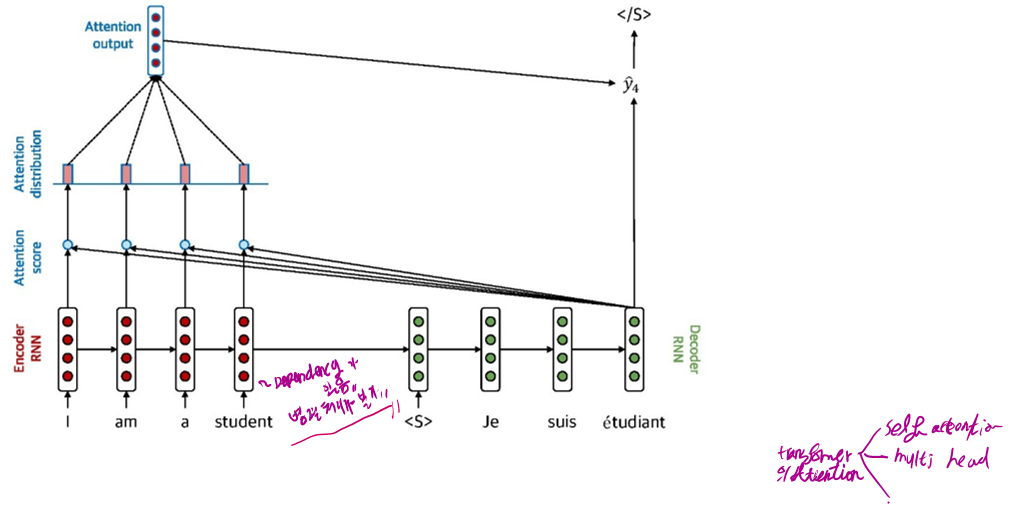
5.2.2.1 Attention: in equations
Encoder Hidden States $h_1, \ldots, h_N \in \mathbb{R}^h$
t 시점에서의 decoder hidden state $s_t \in \mathbb{R}^h$
Attention score $e^t$ 는 다음과 같이 계산
$$
\boldsymbol{e}^t=\left[\boldsymbol{s}_t^T \boldsymbol{h}_1, \ldots, \boldsymbol{s}_t^T \boldsymbol{h}_N\right] \in \mathbb{R}^N
$$
Attention score에 softmax를 적용한 뒤, attention distribution $\alpha^t$ 를 계산
- $\alpha^t$ 는 더해서 1 이 되는 확률 분포
$$
\alpha^t=\operatorname{softmax}\left(e^t\right) \in \mathbb{R}^N
$$
Attention output $\boldsymbol{a}_t$ 은 $\alpha^t$ 와 encoder hidden state의 weighted sum을 통해서 계산
$$
\boldsymbol{a}_t=\sum_{i=1}^N \alpha_i^t \boldsymbol{h}_i \in \mathbb{R}^h
$$
Attention output $a_t$ 와 decoder hidden state $s_t$ 를 concatenate한 뒤, 일반적인 seq2seq모델 처럼 처리 $\left[a_t ; s_t\right] \in \mathbb{R}^{2 h}$
$$
\begin{gathered}
e^t=\left[s_t^T h 1, \ldots, s_t^T h_N\right] \in \mathbb{R}^N \\
\alpha^t=\operatorname{softmax}\left(e^t\right) \in \mathbb{R}^N \\
a_t=\sum_{i=1}^N \alpha_i^t h_i \in \mathbb{R}^h
\end{gathered}
$$

'IT > 수업내용 정리' 카테고리의 다른 글
| ASR_Chapter 4: Recurrent Neural Networks (0) | 2024.08.14 |
|---|---|
| ASR_Chapter 3: Feed Forward Neural Net (0) | 2024.08.13 |
| pattern recognition_Ch 02 Bayesian Decision Theory (1) | 2022.12.21 |
| pattern recognition_ch01 Intro (0) | 2022.12.21 |
| ASR_Chapter 2: 입/출력 end 복잡도 분석 (3) | 2022.11.18 |



