CH01 intro
1.1 기계인지
패턴을 인식은 음성인식, 지문식별, OCR, DNA시퀀스 식별 등 많은 곳에서 유용하다.
패턴인식의 방법론은 자연계, 특히 인간의 패턴 인식 체계에 대해 실제로 자연계가 이 문제를 어떻게 푸는가에 대한 지식에 영향을 받아 이뤄진다.
1.2 보기
예를 들어 생선 통조림 공장에서 생선을 분류하는 과정을 자동화하기를 원한다고 하자.
생선은 컨베이어 벨트에 실려 지나가며, 광학 센서를 이용해서 Sea bass salmon을 분류할 것이며, 카메라를 설치하여 sample 영상을 얻어 두 어종간의 외형적 차이(길이, 밝기, 폭, 지느러미 수와 모양, 입의 위치 등)을 적다보면, 이중 분류기에 사용할 특징이 나올 것이다.
이때, 영상의 노이즈, 또는 변화(밝기, 컨베이어위의 위치,. 잡영(static))도 주목해야 할 것이다.

Sea bass와 Salmon의 모집단 간에 차이가 있다는 사실이 주어지면, 이들을 (보통 수학적 형태인 다른 묘사들)모델로 본다.
Pattern classification에서 전체를 지배하는 목표와 방식은 이 모델들의 class를 가정하고, 감지된 data를 처리해서 노이즈를 제거한 뒤, 감지된 모든 pattern에 대해 가장 잘 일치하는 모델을 선택하는 것이다.
전처리 과정에서는 segmentation 연산이 가능한데, 이때, 배경분리, 서로간에 분리가 이뤄진다.
이후 그 정보들이 Feature 추출기로 가면, 어떤 특징, 특성을 측정해서 데이터를 축소한다.
이 값들이 분류기도 가면, 이것들을 평가하고, 최종적으로 어종에 대한 판정을 내린다.
그렇다면 이 특징 추출기와 분류기가 어떻게 설계될 것인가를 고려하자면, 누군가가 Sea bass가 Salmon보다 더 길다고 정보를 알려줬다면, 이 사실은 이 어류에 대한 모델을 제공한 것이다.
모델: Seabass는 어떤 전형적 길이를 가지고, 그 길이는 Salmon보다 크다. 따라서 길이는 분명한 특징이 되며, 생선의 길이 $ l $을 통해 분류를 시도할 수 있을 것이다.
이를 위해 sample을 얻고 측정하고 결과들을 살펴보면 그림 1.2와 같다.
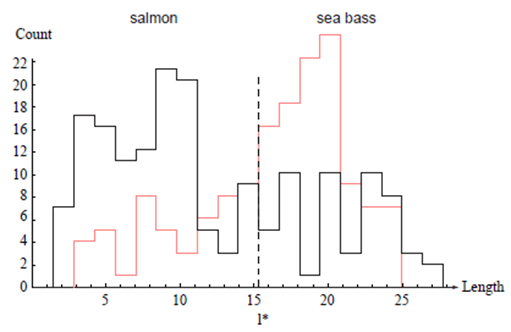
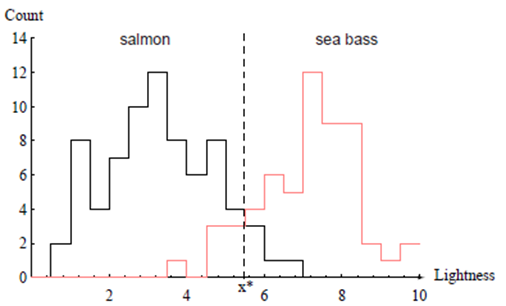
그림 1.2에서는 Seabass가 Salmon보다 다소 긴 것을 알려주지만, 사실 신뢰성은 떨어진다.
이번엔, 그림 1.3과 같이 밝기로 시험을 해보니, 상당히 만족스럽게 나옴을 알 수 있다.
다만, 이제까지 분류의 결과들은 비용이 같다고 가정되었다. 예를들어 Salmon을 Seabass로 판정하는 것과 그 역이 동일하다는 것.
하지만, Seamon을 샀는데 Seabass가 들었다면 더 강력한 항의가 있을 것이기에 이 비용은 현실적에서는 맞지 않다.
따라서 decision boundary를 왼쪽으로 더 이동시켜 Salmon으로 분류되는 Seabass의 수를 줄여야 한다. 이는 비용에 따라 더 왼쪽으로 이동할 수도, 오른쪽으로 이동할 수도 있다.
본질적으로 이러한 비용을 최소화하도록 판정경계를 나누는 것이 decision theory의 핵심이다.
판정과 관련된 비용을 알고 있어 최적의 기준 값 x*을 선택했다 해도, 결과가 만족스럽지 않다면, 더 나은 성능을 제공할 방법을 찾아야 한다. 즉, 여러 특징에 의존하게 된다.
이번엔, Seabass가 일반적으로 Salmon보다 폭이 더 넓다는 사실을 이용해보자.
밝기 $x_1$ 과 폭 $x_2$ 를 2차원 특징 공간의 점 또는 vector x로 축소시킨다. $x=\left(\begin{array}{l}x_1 \\ x_2\end{array}\right)$
이제 문제는 이 특징공간을 두 영역으로 나누는 것이고, 한 영역의 모든 점은 Seabass, 다른 영역은 Salmon이 될 것이다.
sample에서 그림 1.4의 분포를 얻었다고 하자.

이 결과를 보면, 더 많은 특징을 사용하는 것이 꽤나 바람직하다. 이외에도 등지느러미의 꼭대기 각도, 눈의 배치(입-꼬리까지의 거리에 대한 비)같은 특징을 포함시킬 수 있을 것이다.
다만, 이 특징들은 중복될 수도 있고, 어떤 특징은 성능향상이 없을수도 있으며, 차원의 저주를 야기할 수 있다. 또한 측정 비용도 무시못할 요소이다.
그래서 두 특징들에 판정을 내리도록 강요된다 가정해보자. 만약 모델이 너무 복잡하다면, 그림1.5와 같은 복잡한 판정경계를 갖는다.

이 경우 sample은 완벽히 분류하겠지만 새로운 패턴에는 정확도가 떨어질 것이다. 이것이 일반화(General-Ization)에 대한 이슈이다.
사실상 그림 1.5는 특정 패턴에 과적합 되어 있다. 해결방법은 더 많은 학습 샘플을 구하는 것이지만, 이게 어려울 때는 다른 방법을 사용해야 한다.
그렇기에 실제 자연은 복잡한 판정경계가 아닐 것이라는 확신을 가지고 단순화한 것이 그림 1.6이다.

이 경우 새로운 데이터에 더 좋은 결과를 보인다면, sample에 대해 조금 저조해도 만족할 수 있을 것이다. 하지만, 더 간단한 분류기가 좋다는 것을 어떻게 뒷받침할까?
그림 1.4가 1.5보다 좋다고 말할 수 있는가? 이 절충관계를 어떻게든 최적화할 수 있다고 가정하면, 시스템이 모델을 얼마나 잘 일반화할 수 있을것인지를 예측할 수 있는가? 이것이 바로 통계적 패턴 인식의 핵심 문제에 속한다.
우리의 판정은 특정 작업, 비용을 위한 것이며, 범용성을 가지에 만든다는 것은 어려운 도전이다.
기본적으로 분류는 그 패턴들을 만든 모델을 복구하는 작업이기에, 모델의 유형에 따라 분류 기법은 달라질 수 있다.
이러한 기법은 NeuralNet, 통계적 인식, 구문론적 패턴 인식 등 다양한 방법이 있다.
다만 거이 모든 문제에서의 중점은 구성성분간 구조적 관계가 간단하고 자연스레 드러나며, 패턴의 전형적 모델이 나타내질 수 있는 좋은 표현을 달성하는 것이다.
경우에 따라 패턴들은 실수값의 vector, 정렬된 속성, 관계에 대한 표사로 표현될 것인데, 어쨌든 비슷한 애들끼리는 서로 가까이 있고, 다른 애들끼리는 멀리 있게 되는 표현을 찾는 문제라 할 수 있다.
reference: 김경환 교수님 패턴인식 강의, duda pattern recognition
'IT > 수업내용 정리' 카테고리의 다른 글
| AIE_6208_pattern recognition_Ch 02 Bayesian Decision Theory (1) | 2022.12.21 |
|---|---|
| CSE_5311_Chapter 2: 입/출력 end 복잡도 분석 (0) | 2022.11.18 |
| CSE_5311_Chapter 01: 음성인식 연구 동향 및 문제 정의 (1) | 2022.11.18 |



