이래저래, 공부를 너무 대충하는 것 같아 참조차 적어보기 위해 만든 블로깅
머신 러닝의 숲을 먼저 살펴보자면, 알고리즘까지 나열하자면 지금은 한도끝도 없이 많다.
다만, 어떤 식으로 분류가 되는지에 대해서는 원형 까지인데, 이정도는 알고있는것이 좋을 것 같다.

먼저 정통적인 방식은 Supervised Learning인데,
지도학습은 레이블이 있는 상태에서 학습하는 방식으로써, 학습데이터로 주어진 데이터의 피처와 레이블값을 머신러닝 알고리즘으로 학습, 모델을 생성하고, 이 모델에 피쳐를 줬을 때의 레이블 값을 예측하는 것이다.
여기에는 분류와 회귀가 있다.
분류는 결정트리, KNN, SVM, Navie Bayes, Neural net등의 다양한 알고리즘이 있으며 Ensemble이란 알고리즘을 결합하여 예측을 수행하는 방식으로 베깅, 부스팅, 볼팅 등이 있다.
Random forest 경우도 결정트리를 부스팅한 것으로써, Xgboost, LightGBM 또한 결정트리의 일종이라고도 볼 수 있다.
https://www.robotstory.co.kr/raspberry/?board_name=raspberry_bbs&mode=list&search_field=fn_user_pid&search_text=426&board_page=2&list_type=list&lang=ko_KR
결정트리
결정트리는 이해하기 쉬운 알고리즘으로써, 데이터에 있는 규칙을 학습으로 찾아내 트리 기반의 분류 규칙을 만드는 것이다. 단순하게 말하면 분기문을 만들어 구분한다고 생각하면 되겠다.

결정 트리의 경우 루트노드, 규칙이 있는 서브노드와 결정된 값이 들어있는 리프노드가 있다. 그리고 새로운 규칙이 추가될때 이에 기반한 서브트리가 생성된다.
이때, 많은 규칙이 있다는 것은 분류를 결정하는 방식이 복잡하다는 것이고, 이는 과적합, 성능저하의 원인이 된다.
결정트리의 핵심 아이디어는 불순도를 낮추는 것에 있다. 불순도란 정보의 복잡도(얼마나 균일한가)를 의미하며, 불순도를 수치화한 값에는 지니계수(Gini coefficient)와 엔트로피(Entropy)가 사용된다.
아무래도, 동일한 데이터에서도 결정트리는 여러 개가 나올 수가 있는데, 여기서 불순도를 이용해 더 효과적인 결정트리를 결정할 수 있다.
subNode에서 데이터가 분리되었을 때, 더 순도가 높은 데이터가 많이 나오게 되는 속성이 더 효과적이라고 할 수 있으며, 이때 순도가 높다는 것은 분류된 레이블 값이 동일한 것, 즉, 레이블 값이 다 같은 것을 말한다.
이때, 분류가 완료된 리프노드의 엔트로피는 0이다.
Decision Tree의 성능측정은 entropy(T)를 통해 이뤄지며 entropy(T)= -p+log(p+) -p-log(p-)이다.
이때, p+, p-는 각각 positive position(순도가 pure한 것/전체), nagative position(순도가 pure하지 않은 것/전체)를 말한다.
예를 들어 10개 데이터의 클레스를 분류한 결과, 7개는 예측이 잘 되지만 3개는 안된다면
p+, p-는 각각 [7+, 3-]이고, entropy(T)= -(7/10)log(7/10)-(3/10)log(3/10)=0.881 이다. (entropy 는 0to1 이다)
조금 더 살펴보자면, 결정트리 알고리즘에는 ID3, CART가 있는데, 이때 ID3은 엔트로피를 사용하고, CART는 지니계수를 사용한다. (이 내용 공부후 추가할 것)
랜덤 포레스트
랜덤 포레스트란 배깅을 사용하는 앙상블으로써, 배깅은 같은 알고리즘으로 여러 개의 모델을 만들어서 보팅으로 최종 결정하는 알고리즘이다.
기본적인 개념은 여러 개의 결정트리 모델이 전체 데이터를 샘플링해 개별적으로 학습을 수행 한 뒤, 모든 분류기가 보팅을 통해 예측 결정을 하는 방식이다.
이때, 보팅이란 여러개의 모델이 학습하고 예측한 결과를 보팅으로 최종 예측하는 것으로써, 하드보팅과 소프트 보팅이 있다.
하드 보팅은 일종의 다수결 원칙으로, 다수의 모델이 결정한 예측값을 최종 보팅값으로 선정하는 것이고, 소프트 보팅은 모델의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이 중 가장 확률이 높은 레이블 값을 최종 보팅 결과값으로 선정하는 것으로써, 일반적으로 소프트 보팅이 사용된다.
랜덤 포레스트의 모델별 알고리즘은 결정트리이지만, 각각의 모델이 학습하는 데이터는 전체 데이터에서 일부가 중첩되도록 샘플링된 데이터셋이다. 이렇게 여러 개의 데이터셋을 중첩되게 분리하는 것을 부트스트레핑(bootstrapping)분할 방식이라고 하며,

이렇게 부트스트레핑으로 분할된 데이터셋에 결정트리 모델을 각각 적용하는 것이 랜텀 포레스트이다.
GBM
다음으로 GBM을 살펴보면
부스팅 알고리즘이란 여러 개의 약한 학습기를 순차적으로 학습-예측하며 잘못 예측된 데이터에 가중치를 부여하여 오류를 개선하며 학습하는 것이다.
대표적으로 AdaBoost와 GradientBoost가 있다.
KNN
KNN을 먼저 설명하자면 이건 매우 쉽다.
간단하게 가장 가까운 점 몇개를 가지고 분류하겠다는 문제.


예측하고 싶은 data에서 가장 가까운 k개의 이웃을 구하고, 거리를 measure하고, 그들의 class값을 체크한 뒤 조정해서 예측하는 것이다.
다음이 SVM인데, 이는 기본적으로 그룹을 분리하기 위해, 데이터들과 가장 거리가 먼 초평면을 선택하여 분리하는 방법을 말한다.
기본적인 아이디어는 어떻게 공간을 나눌 것인가에서 출발하며,
다음 블로그를 참조했다.
https://ratsgo.github.io/machine%20learning/2017/05/30/SVM3/
Kernel-SVM · ratsgo's blog
이번 글에서는 서포트 벡터 머신(SVM)의 변형인 Kernel-SVM에 대해 살펴보도록 하겠습니다. 이 글 역시 고려대 강필성 교수님과 역시 같은 대학의 김성범 교수님 강의를 정리했음을 먼저 밝힙니다. S
ratsgo.github.io
[머신러닝 정리] 서포트 벡터 머신(Support Vector Machine) - 05. Why does SVM maximize margin?
본 포스팅 시리즈는 다양한 머신러닝 테크닉에 대해 수학적 관점과 실용적 관점에서 정리한다.
velog.io
https://www.slideshare.net/freepsw/svm-77055058
내가 이해하는 SVM(왜, 어떻게를 중심으로)
Coursera Machine Learning by Andrew NG 강의를 들으면서, 궁금했던 내용을 중심으로 정리. 내가 궁금했던건, 데이터를 분류하는 Decision boundary를 만들때... - 왜 가중치(W)와 decision boundary가 직교해야 하는지
www.slideshare.net
https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
초짜 대학원생의 입장에서 이해하는 Support Vector Machine (1)
Machine learning and research topics explained in beginner graduate's terms. 초짜 대학원생의 쉽게 풀어 설명하는 머신러닝
jaejunyoo.blogspot.com
https://sanghyu.tistory.com/7?category=1122189
먼저 SVM을 설명하기 전에, 선형분류에 대해 얘기를 하는 것이 이해에 도움이 될 것 같다.
간단히 두개의 클레스를 분류하는 문제를 생각해보면,
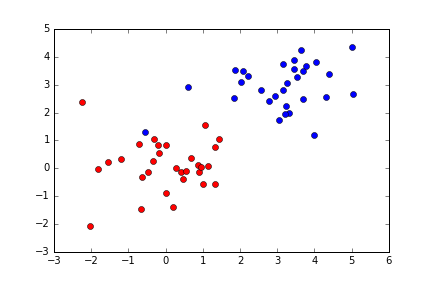
위와 같은 데이터가 주어졌을 때, 이를 분류하기 위한 선을 하나 그어보자면
아래와 같은 모양이 될 것이다.
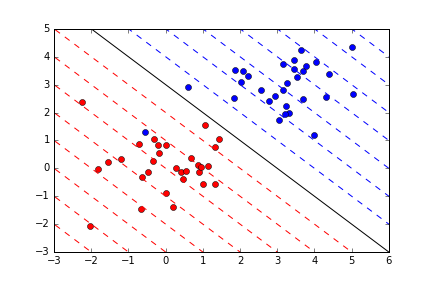
이고, $$y=w_{1}x_{1}+b$$꼴의 식이 만들어 질 것이고, 이때, $$y=-x+6$$이라면, 위의 선중 실선이 될 것이다.
여기서 식을 조금 다르게 바라보자
가로축, 세로축이 각각 $$x_{1},x_{2}$$ 라고 한다면, $$y=w_{1}x_{1}+w_{2}x_{2}+b$$꼴이 될 것이고, 각각을
선형 분류는 가장 적절한 경계선이 되도록 w와 b를 결정하는 것이다.
이 적절함은 손실함수로 찾을 수 있다.
여기서 발전한 형태가 피셔의 판별분석이라 할 수 있다.
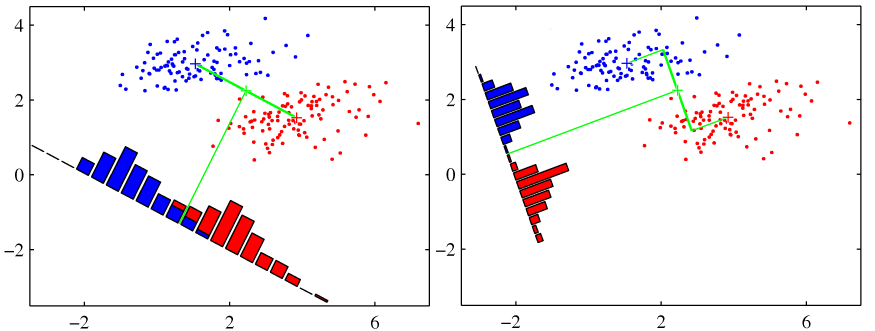
위의 그림에서 왼쪽 그림이 오른쪽 그림보다 평균간의 거리는 더 멀지만, 경계선은 오른 쪽이더 적합해 보인다.
원인은 왼쪽은 클래스의 y값이 넓지만, 오른쪽은 좁게 모여있기 때문으로, 선형판별분석은 클래스간의 차이는 크게, 클래스 내의 차이는 작게 만드는 w를 가장 좋은 w로 본다.
정리하면 아래의 식에서 J를 최대화하는 w를 찾는 것이다.
$$J=\frac{(m_{1}-m_{2})^{2}}{s_{1}^{2}+s_{2}^{2}}$$
$$m_{i}:i번째 클래스의 평균, s_{i}:i번째 클래스의 표준편차$$
이런 아이디어가 선형분류라고 한다면,
SVM은 클래스를 나누는 선과 가장 가까운 점의 거리를 최대화하는 것이 아이디어다.
선형 판별을 할 때, 클래스를 나누는 선은 여러 개가 나올 수 있는데, 이중 어떤 것을 선택할 것인지에 이 아이디어가 쓰이는데,
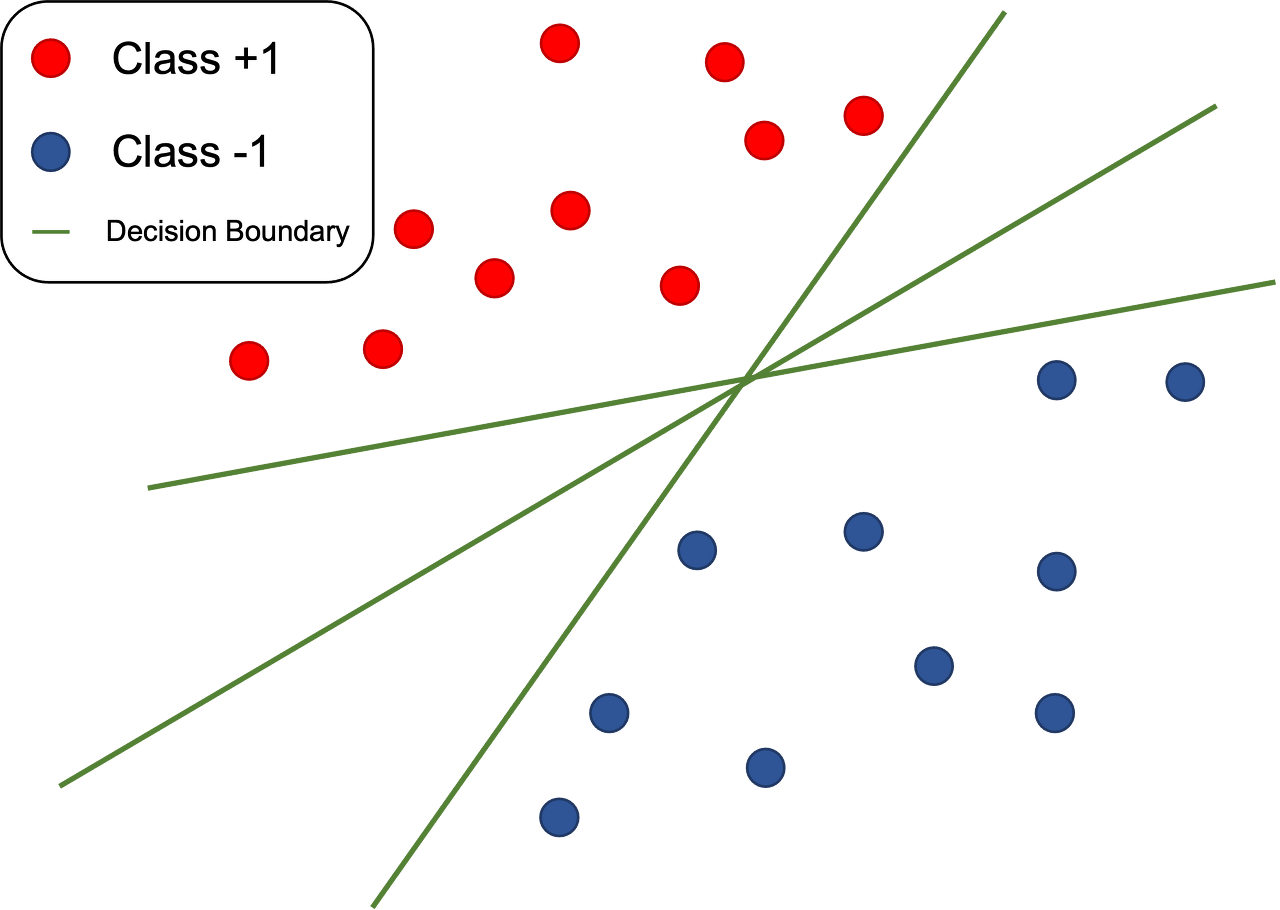
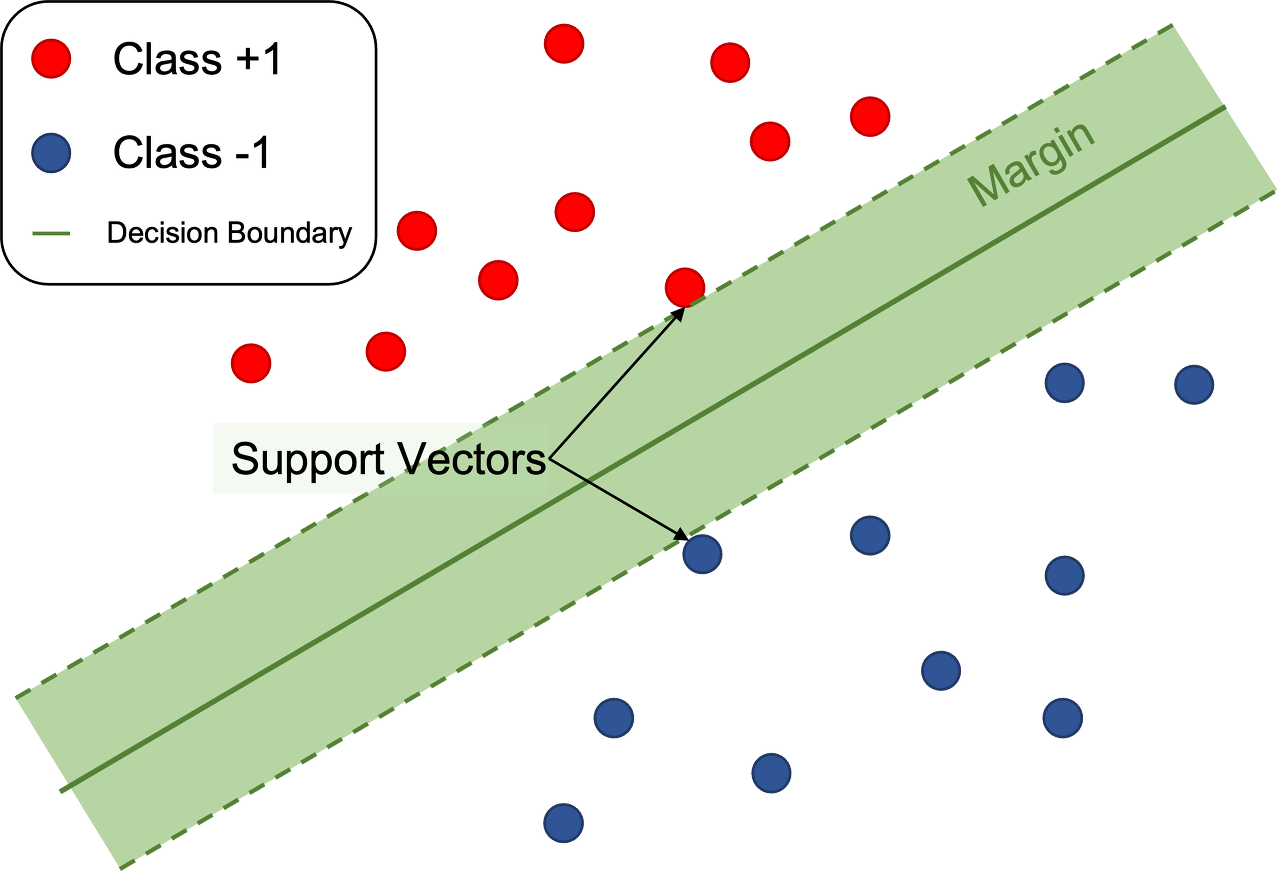
위의 그림에서 아래 그림이 SVM에 대해 잘 설명하고 있다. 선에서 가장 가까운 점이 Support Vectors이고, Margin이 선과 SupportVectors와의 거리를 말한다.
이 마진을 결정하는 각 클래스의 샘플이 서포트 벡터이며, 새로운 데이터가 들어왔을 때 클래스를 구분하는 기준이 된다.
이 거리가 멀수록 신뢰도가 올라가게 되고 이 거리를 최대화하는 것을 하드마진이라 한다.
다만 이 SVM의 단점이라 한다면, 실제 데이터에서 노이즈나 이상치에 대처가 어렵다는 것이다.
그래서 소프트 마진이라는 것이 생기게 되었는데,
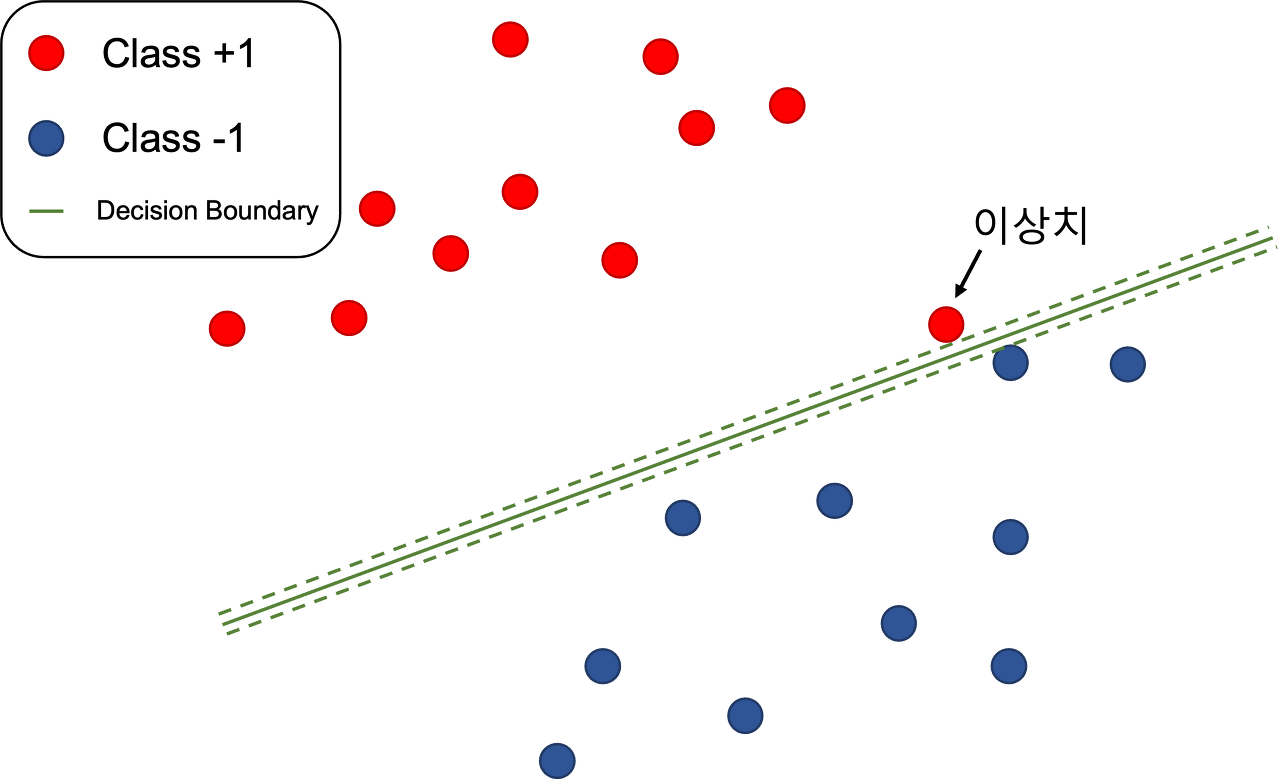
위와 같은 그림이 현실에 가까운 데이터라 할 수 있으며, 하드마진은 이에 대응하기가 어렵다.
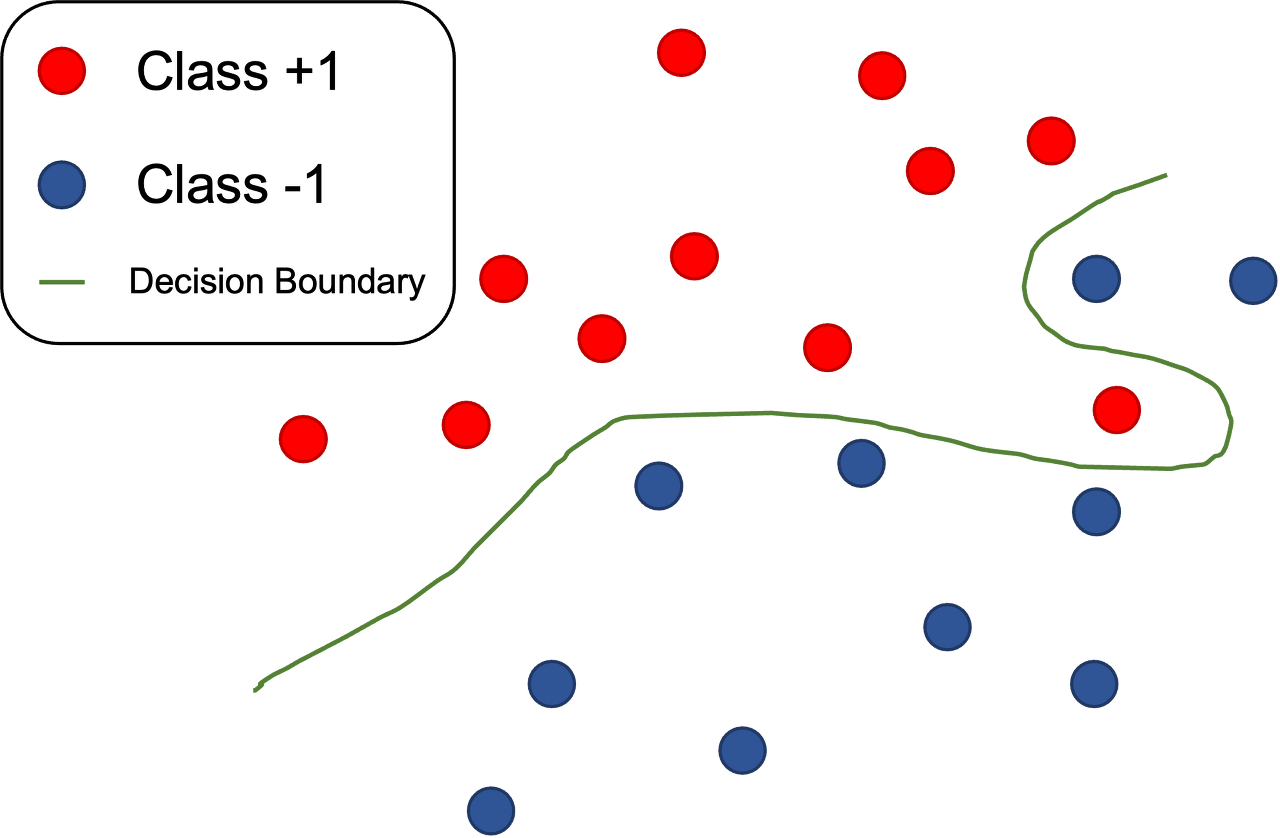
또한 위의 사진과 같이 선형 분류가 되지 않는 경우는...... 사실상 성능을 낼수가 없다.
따라서, 마진에 잉여(slack)를 허가해 줌으로써 개선한 것이 소프트 마진 svm이다.
훈련 데이터에 이상치나 노이즈가 있다는 점에 무게를 두고, 결정경계의 근방에서 발생할 노이즈, 이상치는 좀 틀려도 되도록 여유를 주고 넓은 마진을 가지게 하는 것이다.
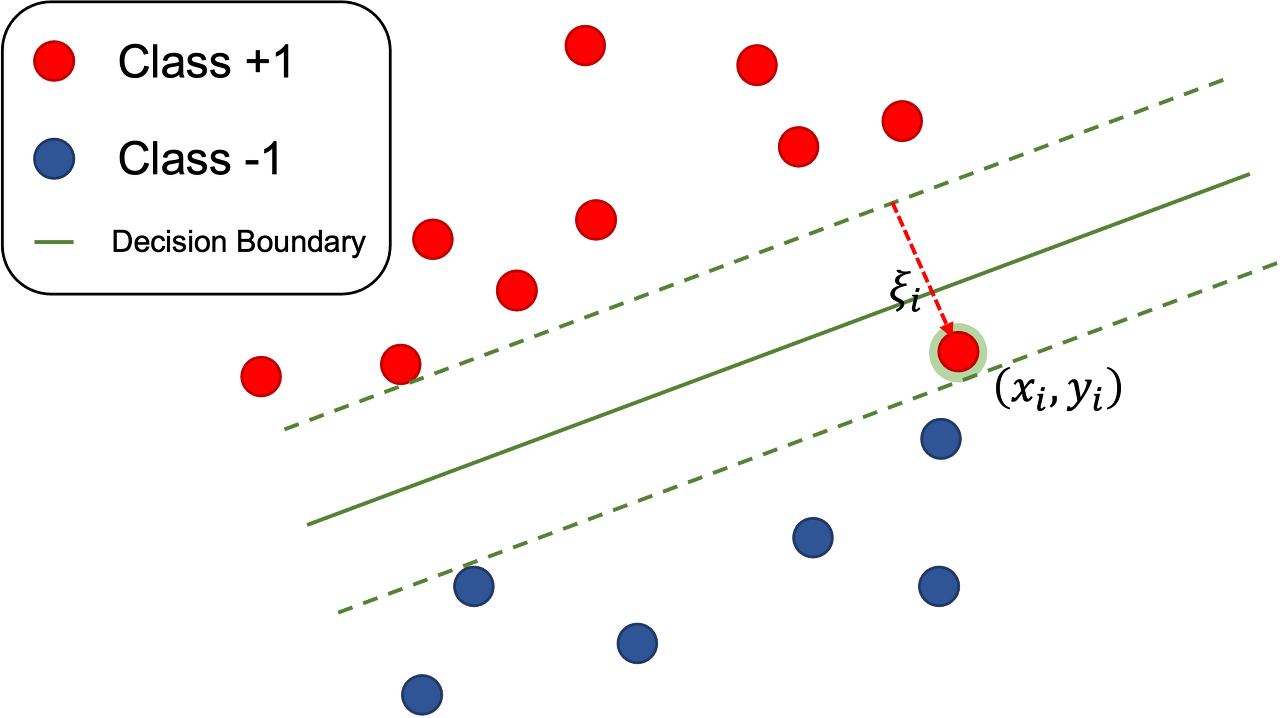
각 훈련 데이터 샘플 $$(x_{i},y_{i})$$마다 잉여 변수를 대응시켜, 샘흘이 마진의 폭 안으로 $$ξ_{i}$$만큼 파고드는 것을 용인해주는 것이다.
-커널트릭
eigen vector을 잘 설명해주는 그림이 있어 위키피디아에서 가져왔다.

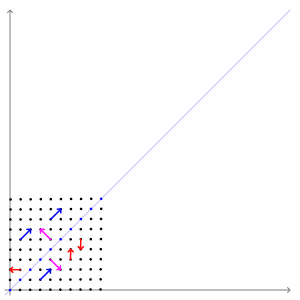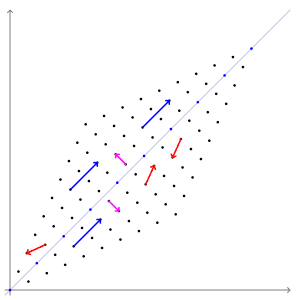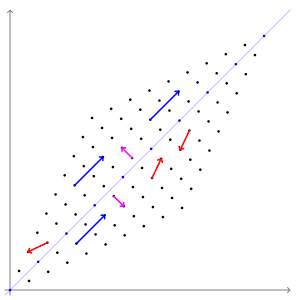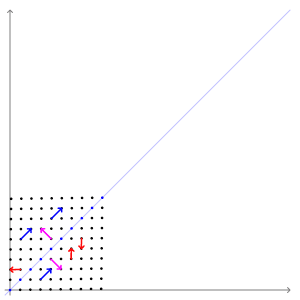
SVM
Naive Bayes
다음으로 Naive Bayes Learning을 살펴보면,
기본적 아이디어는 조건부 확률을 말하는 것으로 예를 들어 2개의 random x,y가 있을 때 x의 조건하에 y일 확률을 말한다.
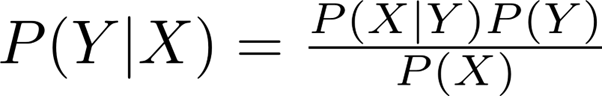
즉 어떤 x가 주어졌을 때 어떤 클래스에 속할 확률을 구해서 그중 가장 큰 확률을 주는 x가 y라고 보겠다는 것이다.
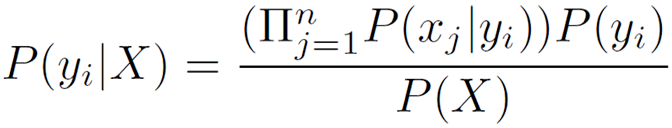
예를 들자면,
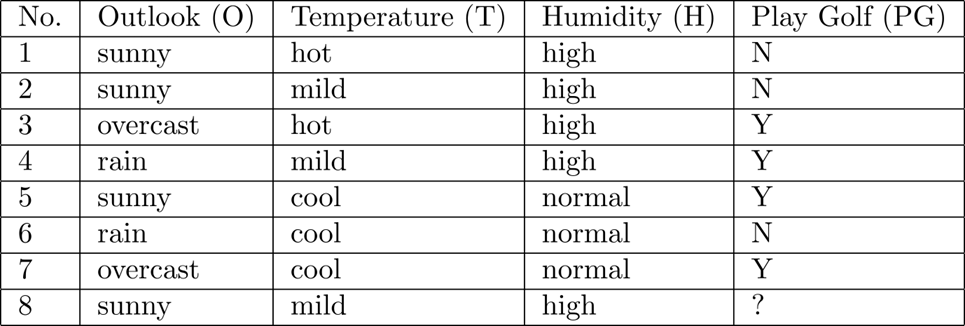
위와 같은 표가 주어진다고 하자.
8번째에서 내가 골프를 칠 것인가를 결정하자면\[\sum_{n=1}^{100} {n}\]
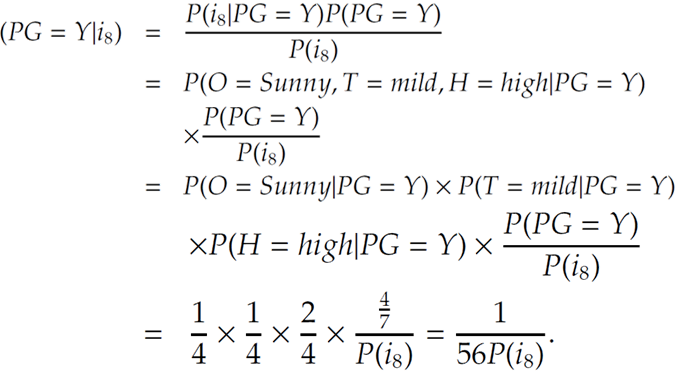
골프를 칠 것인가가 Yes일 떄의 확률은 $$\frac{sunny}{Y일때}\frac{mild}{Y일때}\frac{high}{Y일때}\frac{\frac{Y}{전체}}{P(i_{8})}=\frac{1}{4}\frac{1}{4}\frac{2}{4}\frac{\frac{4}{7}}{P(i_{8})}=\frac{1}{56P(i_{8})}$$ 이고,
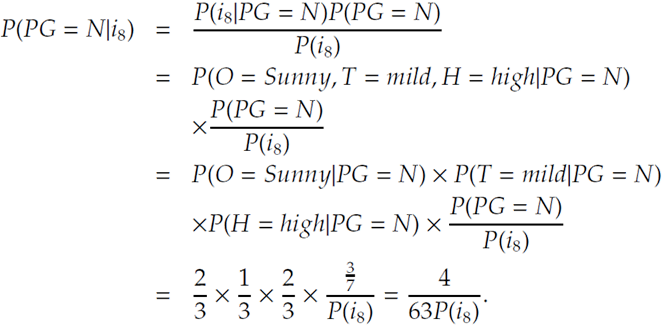
골프를 칠 것인가가 No일 떄의 확률은
$$\frac{sunny}{N일때}\frac{mild}{N일때}\frac{high}{N일때}\frac{\frac{N}{전체}}{P(i_{8})}=\frac{2}{3}\frac{1}{3}\frac{2}{3}\frac{\frac{3}{7}}{P(i_{8})}=\frac{4}{63P(i_{8})}$$
이 나온다.

이때, N일 때가 더 크므로 골프를 치는가의 여부는 N으로 결정된다.
'IT' 카테고리의 다른 글
| (작성중)Social Media Mining #1 introduction, #2 Graph Essentials (0) | 2022.07.08 |
|---|---|
| 낡은 nas j4105로 교체기. (4) | 2018.02.26 |



