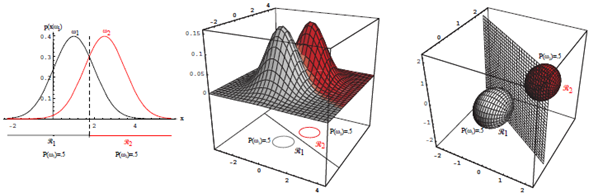
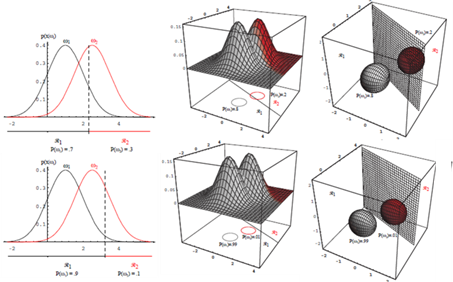
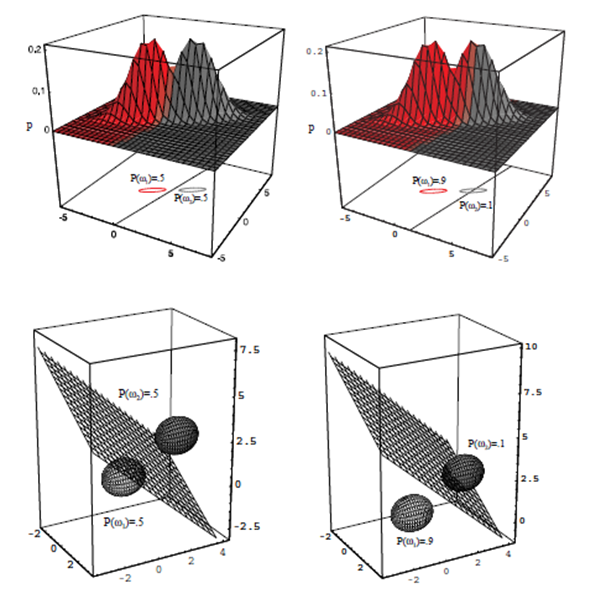
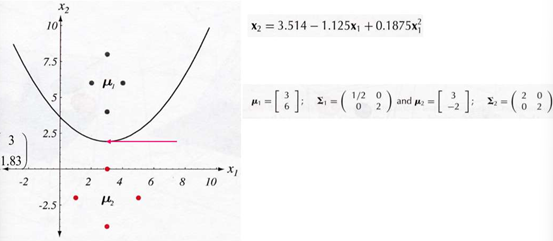이때 이 두부류의 경우는 $p(x)=\sum_{j=1}^2 p\left(x \mid \omega_j\right) P\left(\omega_j\right)$. posterior $=\frac{\text { likelihood } \times \text { prior }}{\text { evidence }}$
Bayes 공식은$x$ 의 값을 관찰함으로써 사전확률prior을 사후확률posterior(특징$x$ 가 측정되었을 때 자연 상태가$\omega_j$ 일 확률) 로 전환할 수 있다. $p\left(x \mid \omega_j\right)$는 $x$에 대한 $\omega_j$의 우도(likelihood)라고 부른다.
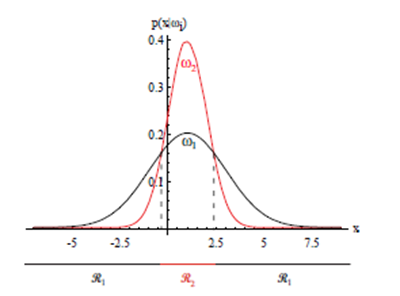
클레스 조건부 확률 밀도에 대한 특정 사정 확률에 대한 사후 확률. 모든 x에서 사후확률의 합은 1.0이다.
$P\left(\omega_1\right)=\frac{2}{3}$ and $P\left(\omega_2\right)=\frac{1}{3}$
Probability of error when decision is made
결정 방법은 $P($ error $\mid x)=\left\{\begin{array}{l}P\left(\omega_1 \mid x\right) * \text { if decide } \omega_2 \\ P\left(\omega_2 \mid x\right) * \text { if decide } \omega_1\end{array}\right.$
- 결정을 내릴 때 오류가 나올 확률은,$P($ error $)=\int_{-\infty}^{\infty} p($ error,$x) d x=\int_{-\infty}^{\infty} P($ error $\mid x) p(x) d x$ 만일 모든 x에 대해 $P(\operatorname{error} \mid x)$ 를 작게 만든다면 이 적분은 가능한 작아야 한다.
Bayes Decision Rule (for minimizing the probability of error)
- Decide $\omega_1$ if $p\left(\omega_1 \mid x\right) P\left(\omega_1\right)>p\left(\omega_2 \mid x\right) P\left(\omega_2\right) ; \omega_2$ 로 판정 otherwise
- $\boldsymbol{p}(\boldsymbol{x})$ : 는 결정에 있어서는 크게 중요하지 않음 $\left(P\left(\omega_1 \mid x\right)+P\left(\omega_2 \mid x\right)=1\right)$
Decide $\omega_1$ if $p\left(\omega_1 \mid x\right) P\left(\omega_1\right)>p\left(\omega_2 \mid x\right) P\left(\omega_2\right) ; \omega_2$ 로 판정 otherwise
사후 확률의 역할을 강조. - 만일 어떤 x에 대해서$p\left(x \mid \omega_1\right)=p\left(x \mid \omega_2\right)$라면판정은전적으로사전확률에의해정해진다. - $P\left(\omega_1\right)=P\left(\omega_2\right)$라면판정은전적으로우도$p\left(x \mid \omega_j\right)$에근거하게된다.
Bayesion decion theory – continuious features(연속적 특징)
Bayesian Theory의 일반화
-둘 이상(more than one feature)의 특징을 사용하는 것을 허용하는 것 - 스칼라 x
를 특징vector x
로 대체 - x
는 특징공간이라고 부르는 d
-차원 유클리드 공간 Rd
에 속함
Bayesion decion theory – continuious features(연속적 특징)
Bayesian Theory의 일반화
-둘 이상(more than one feature)의 특징을 사용하는 것을 허용하는 것 - 스칼라 x 를 특징vector x 로 대체 - x 는 특징공간이라고 부르는 d-차원 유클리드 공간 $\mathbb{R}^d$에 속함
- 셋 이상(more than two states)의 자연의 상태를 허용하는 경우
- $\left\{\omega_1, \ldots, \omega_c\right\}: c$개의 자연의 상태(“categories”)의 유한 집합
- 분류 외의 행동을 허용하는 것
- $\left\{\alpha_1, \ldots, \alpha_a\right\}$: a개의 가능한 행동의 유한 집합
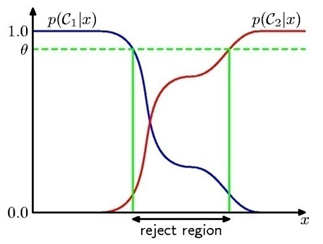
그림은 분류기준을 만들 때, 일정 수준 이하는 결정을 못하게 하는경우. - 사람이 해야함 .....확실한 것만 분류기가 분류하게 한다.
- 오류 확률(probability of error)보다 더 일반적이라 할 수 있는 손실 함수(loss function)를 도입. - 손실 함수는 각 행동의 비용을 정확하게 나타내며, 확률 측정을 판정으로 전환에 사용된다. $\lambda\left(\alpha_i \mid \omega_j\right)$ : 자연의 상태가 $\alpha_i$ 일 때, $\omega_j$ 라는 행동을 취해서 초래되는 손실
행동 $\alpha_i$를 취하는 것과 관련된 기대 손실은 단순하게 $R\left(\alpha_i \mid x\right)=\sum_{j=1}^c \lambda\left(\alpha_i \mid \omega_j\right) P\left(\omega_j \mid x\right)$
-판정-이론 용어로는 기대 손실을 리스크라고 부르며, $R\left(\alpha_i \mid x\right)$를 조건부 리스크라고 부른다.
- 문제는 $P\left(\omega_j\right)$에 대해 전체적 리스크를 최소화하는 판정 룰을 찾는 것.
$R=\int R(\alpha(x) \mid x) p(x) d x \quad R$ : 최소화된 전체적 리스크
- 전체적 리스크를 최소화하기 위한 조건부 리스크 계산 $R\left(\alpha_i(x)\right)$ 가 가능한 작도록 $\alpha(x)$가 선택된다면 전체적 리스크는 최소화
$i=1, \ldots, a$ 에 대해 계산하고, $R\left(\alpha_i \mid x\right)$ 가 최소인 행동 $\alpha_i$ 를 선택
Bayesion decion theory – 두 부류(Two-Category) 분류
- $\alpha_1$: 자연의 참 상태가 $\omega_1$ 이라고 판정을 내리는 것
-$\alpha_2$: 자연의 참 상태가$\omega_2$ 이라고 판정을 내리는 것
- $\lambda_{i j}=\lambda\left(\alpha_i \mid \omega_j\right)$: 자연의 참 상태가 $\omega_j$일 때 $\omega_i$라고 판정시 따르는 손실 이를 적용해서 $R\left(\alpha_i \mid x\right)=\sum_{j=1}^c \lambda\left(\alpha_i \mid \omega_j\right)\left(\omega_j \mid x\right)$ 를 다시 쓰면
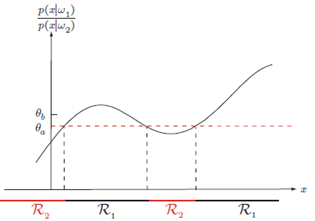
- 최소 리스크 판정 룰을 표현하는 다양한 방법 1. $R\left(\alpha_1 \mid x\right)<R\left(\alpha_2 \mid x\right)$ 이면 $\omega_1$ 로 판정 2. $\left(\lambda_{21}-\lambda_{11}\right) P\left(\omega_1 \mid x\right)>\left(\lambda_{12}-\lambda_{22}\right) P\left(\omega_2 \mid x\right)$ 일 때 $\omega_1$ 이라고 판정(사후확률로 표현) 3. $\left(\lambda_{21}-\lambda_{11}\right) p\left(x \mid \omega_1\right) P\left(\omega_1\right)>\left(\lambda_{12}-\lambda_{22}\right) p\left(x \mid \omega_2\right) P\left(\omega_2\right)$ 이면 $\omega_1$ 로 판정하고 아니면 $\omega_2$ 로 판정 (Bayes공식을 사용함으로 사후 확률을 사전 확률과 조건부 밀도로 대체) 4. $\lambda_{21}>\lambda_{11}$ 이라는 논리적 가정 하에서 만약 $\frac{p\left(x \mid \omega_1\right)}{p\left(x \mid \omega_2\right)}>\frac{\lambda_{12}-\lambda_{22}}{\lambda_{21}-\lambda_{11}} \frac{P\left(\omega_2\right)}{P\left(\omega_1\right)}$ 이면 $\omega_1$ 로 판정
(Likelihood ratio: 이 형태의 판정 룰은 확률 밀도들의 $x$-종속성에 초점을 맞춘다. $p\left(x \mid \omega_j\right)$ 를 $\omega_j$ 의 함수(즉, 우도 함수)로 간주하고 우도 비 $\frac{p\left(x \mid \omega_1\right)}{p\left(x \mid \omega_2\right)}$ 를 만들 수 있다. 따라서 Bayes 판정 룰은 관찰 $x$ 에 독립적인 어떤 문턱 값을 우도비가 넘으면 $\omega_1$ 로 판정할 것을 요구하는 것으로 해석)
Bayesion decion theory – Minimum-error-rate Classification(최소 에러율 분류)
에러를 피하기 위해서는 자연의 상태와 차이가 가장 적은(오류를 최소화하는) 판정 룰을 찾는 것이 당연하다.
Zero-One loss function
$\lambda\left(\alpha_i \mid \omega_j\right)=\left\{\begin{array}{ll}0 & i=j \\ 1 & i \neq j\end{array} i, j=1, \ldots, c\right.$
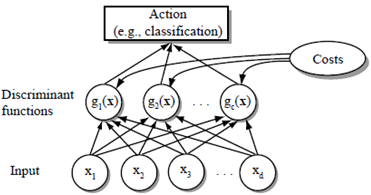
- 만일 $\boldsymbol{g}_{\boldsymbol{i}(\boldsymbol{x})}>\boldsymbol{g}_{\boldsymbol{j}}(\boldsymbol{x}) \forall \boldsymbol{j} \neq \boldsymbol{i}$ 이면 특징 벡터 $x$ 를 클레스 $\omega_i$ 에 할당한다.
분류기
-분류기는 c개의 판별 함수를 계산하고 최대 판별식에 해당하는 부류를 선택하는 네트워크 또는 기계
$g_i(x)=\left\{\begin{array}{c}g_1(x)=0.1 \\ g_2(x)=0.05 \\ \vdots \\ g_{n(x)}=0.85\end{array}\right.$ 중 가장 큰 것 선택
판정에 영향을 주지 않고 우리는 항상 모든 판별 함수들을 같은 양의 상수로 곱하거나 같은 상수를 더해서 이동시킬 수 있다. 더 일반적으로는 모든 $g_i(x)$ 를 단조증가함수 $f(\cdot)$ 에 의해 $f\left(g_i(x)\right)$ 로 대체시, 그로인한 분류는 변하지 않는다. 이것은 현저한 분석 및 계산 단순화로 이끌 수 있다.
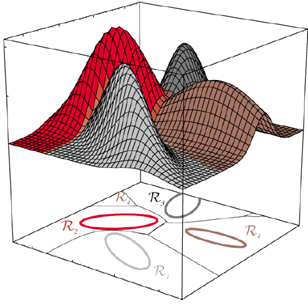
모든 판정 룰의 효과는 특징 공간을 $c$ 개의 판정 영역 $\mathcal{R}_1, \ldots, \mathcal{R}_c$ 로 나누는 것
두 분류 경우
이분기(dichotomizer) 두 부류 경우는 다부류의 일종이나 정통적으로 독립해 다뤄왔다. 두 판별 함수 대신 단일 판별 함수를 정의하고 판정하는 것이 더 보편적이다. $g(x) \equiv g_1(x)-g_2(x)$
$g(x)>0$ 이면 $\omega_1$, 아니면 $\omega_2$ 로 판정 $\boldsymbol{g}(\boldsymbol{x})=\boldsymbol{P}\left(\boldsymbol{\omega}_1 \mid \boldsymbol{x}\right)-\boldsymbol{P}\left(\boldsymbol{\omega}_2 \mid \boldsymbol{x}\right)$ $\boldsymbol{g}(\boldsymbol{x})=\ln \frac{\boldsymbol{p}\left(\boldsymbol{x} \mid \boldsymbol{\omega}_1\right)}{\boldsymbol{p}\left(\boldsymbol{x} \mid \boldsymbol{\omega}_2\right)}+\ln \frac{\boldsymbol{P}\left(\boldsymbol{\omega}_1\right)}{\boldsymbol{P}\left(\boldsymbol{\omega}_2\right)}$
The normal density
왜 Normal density인가?
-분석의 용이함(해석학적으로 다루기 쉬움)으로, 다변량 normal밀도, 또는 Gaussian밀도는 많은 관심을 받았다.
-중요한 상황에 적합한 모델. class $\omega_j$에 특징벡터 x가 단일 또는 프로토타입 벡터 $\mu_i$의 연속적 값을 가지고 랜덤하게 오염된 버전일 경우에 적합.
Expectation (expected value) $$ E[f(x)]=\int_{-\infty}^{\infty} f(x) p(x) d x $$ 만약 특징 $\mathrm{x}$ 의 값들이 이산 집합 $\mathrm{D}$ 의 점이라면. $$ E[f(x)]=\sum_{x \in D} f(x) P(x) $$
- 평균 $$ \mu=E[x]=\int_{-\infty}^{\infty} x p(x) d x $$ - 분산 $$ \begin{aligned} & \sigma^2=E\left[(x-\mu)^2\right]=\int_{-\infty}^{\infty}(x-\mu)^2 p(x) d x \\ & -\quad \boldsymbol{p}(\boldsymbol{x}) \sim \boldsymbol{N}\left(\boldsymbol{\mu}, \boldsymbol{\sigma}^2\right) \end{aligned} $$ $x$ 는 평균 $\mu$ 와 분산 $\sigma^2$ 에 의해 분포된다.
The normal density – 다변량 분포
$$ p(\boldsymbol{x}) \sim N(\boldsymbol{\mu}, \boldsymbol{\Sigma}) \quad p(\boldsymbol{x})=\frac{1}{(2 \pi)^{d / 2}|\boldsymbol{\Sigma}|^{1 / 2}} \exp \left[-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^t \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right] $$ - 평균 벡터 $$ \text { - } \boldsymbol{\mu}=E[\boldsymbol{x}]=\int_{-\infty}^{\infty} \boldsymbol{x p}(x) d \boldsymbol{x} $$ - 공분산 행렬 (Convariance) $$ \Sigma=E\left[(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^t\right]=\int_{-\infty}^{\infty}(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^t p(x) d x{ }^*[x-\mu]=\left[\begin{array}{lll} \sigma_{11} & & \\ & \ddots & \\ & \sigma_{n n} \end{array}\right] $$ - 통계적 독립성(statistical independence) 만약 $x_i$ 와 $x_j$ 가 통계적으로 독립적이면, $\sigma_{i j}=0$ 일 것이다. 만약 모든 비대각선 요소들이 0 이면, $p(x)$ 는 $x$ 의 요소들에 대한 단변량 노멀 밀도들의 곱으로 축소된다.
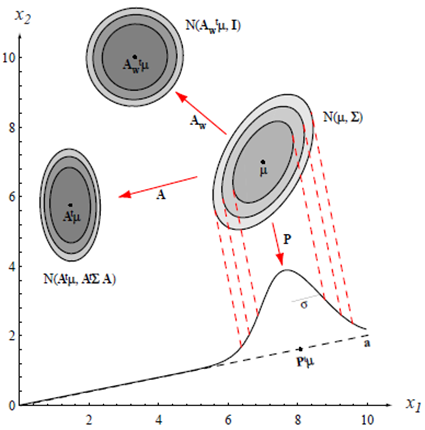
- 독립적이거나 아니거나, 결합적으로(jointly) 노멀하게 분포 하는 랜덤 변수들의 선형 결합(combination)은 노멀하게 분포한다. $$ \begin{aligned} & p(\boldsymbol{x}) \sim N(\boldsymbol{\mu}, \mathbf{\Sigma}) \\ & \boldsymbol{y}=\boldsymbol{A}^t \boldsymbol{x} \rightarrow p(\boldsymbol{y}) \sim N\left(\boldsymbol{A}^{\boldsymbol{t}} \boldsymbol{\mu}, \boldsymbol{A}^{\boldsymbol{t}} \boldsymbol{\Sigma} \boldsymbol{A}\right) \\ & * y=A^t y=\left[\begin{array}{lll} y_1 \\ y_2 \end{array}\right]=\left[\begin{array}{ccc} 1 & \cdots & 0 \\ \vdots & A & \vdots \\ 0 & \cdots & 1 \end{array}\right]\left[\begin{array}{l} x_1 \\ x_2 \end{array}\right] \end{aligned} $$ -임의의 다변량 분포를 구형(spherical)분포로 변환(공분산 행렬이 항등 행렬 $I$ 에 비례하는 분포)할 수 있다. (백색변환) $$ A_\omega=\Phi \Lambda^{1 / 2} $$ $\boldsymbol{\Phi}$ : 열들이 $\Sigma$ 인 정규직교 고유 벡터들인 행렬 $\mathbf{\Lambda}$ : 해당 고윳값들의 대각선 행렬
- 다변량 정규분포는 $\boldsymbol{d}+\boldsymbol{d}(\boldsymbol{d}+\mathbf{1}) / \mathbf{2}$ 개의 파라미터 즉, 평균 벡터 $\boldsymbol{\mu}$ 의 요소들과 공분산 행렬 $\boldsymbol{\Sigma}$ 에 의해 완전하게 정의된다.
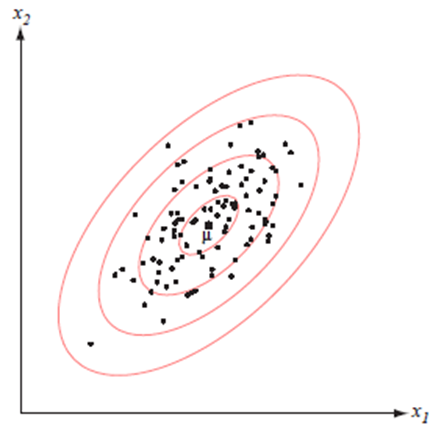
- 아래 그림에서:↓ - 클러스터의 중심은 평균 벡터에 의해 결정 - 클러스터의 모양은 공분산 행렬에 의해 결정. - 상수 밀도의 점들의 위치는 $(\boldsymbol{x}-\boldsymbol{\mu})^t \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})$ 가 상수 인 초타원체들이다 - 이 초타원체들의 주축은 $\Phi$ 에 의해 묘사되는 $\boldsymbol{\Sigma}$ 의 고유 벡터들에 의해 주어지며, 고윳값들 $(\boldsymbol{\Lambda})$ 은 이 축들의 길이를 결정한다. - Mahalanobis distance (from $x$ to $\boldsymbol{\mu}$ ) 마할라노비스 거리 $r^2=(\boldsymbol{x}-\boldsymbol{\mu})^t \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu}) (분산이 커지면, 거리는 작게 해석)
(PRML 2.3) The Gaussian Distribution
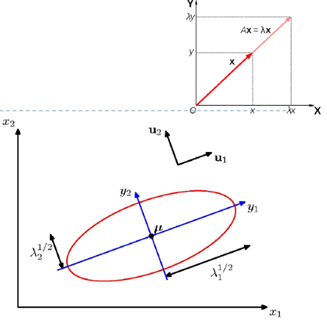
빨간색 선은 이차원 공간 $x=\left(x_1, x_2\right)$ 상에서의 상수 가우시안 확률 분포의 타원형 표면을 나타낸다. 여기서 말도는 $x=\mu$ 일 경우의 값의 $\exp (-1 / 2)$ 에 해당한다. 타원의 축들은 공분산 행렬의 고유 벡터들 $u_i$ 에 의해 정의 되 며, 각각의 축은 각각의 고윳값 $\lambda_i$ 에 대응된다.
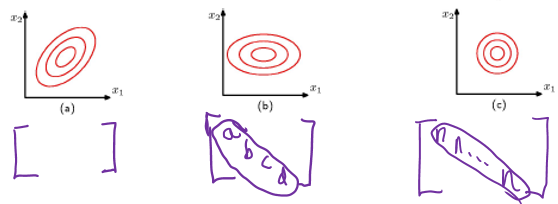
이차원 가우시안 분포에서의 상수확률 밀도의 경로. (a)는 공분산 행렬의 형태가 일반적일 경우 (b)는 공분산 행렬이 대각 행렬인 형태 (c)는 공분산행렬이 항등행렬의 상수배일 경우이며 이 경우 경로가 동심원의 형태를 띈다.
정규분포에 대한 판별 함수
- 최소 에러율 분류는 아래의 판별 함수로 달성될 수 있다. $\begin{aligned} & p(\boldsymbol{x})= \frac{1}{(2 \pi)^{d / 2}|\boldsymbol{\Sigma}|^{1 / 2}} \exp \left[-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^t \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right] \text { 에 의해 } \\ & g_i(\boldsymbol{x})=-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)^t \boldsymbol{\Sigma}_i^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)-\frac{d}{2} \ln 2 \pi-\frac{1}{2} \ln \left|\boldsymbol{\Sigma}_i\right|+\ln P\left(\omega_i\right)\end{aligned}$
- 가장 간단한 경우 - 특징들이 통계적으로 독집적이고 각 특징이 같은 분산 $\sigma^2$를 가짐. - 기하학적으로 샘플들이 같은 크기의 초구 클러스터에 놓이는 상황 - $i$ 번째 클래스에 대한 클러스터는 평균 벡터 $\mu_i$ 가 중심으로 함. - $\Sigma_{\mathrm{i}}$ 의 행렬식과 역의 계산이 쉬움
$\boldsymbol{\Sigma}_i^{-1},\left|\boldsymbol{\Sigma}_i\right|, \ln 2 \pi$ 가 $i$ 에 대해 독립 $$ \rightarrow g_i(x)=-\frac{\left\|x-\mu_i\right\|^2}{2 \sigma^2}+\ln P\left(\omega_i\right) $$ 여기서 $\left\|x-\mu_i\right\|^2=\left(x-\mu_i\right)^t\left(x-\mu_i\right)$ 이며, 유클리드 놈을 나타냄.
$\mathbf{w}^t\left(\mathbf{x}-\mathbf{x}_0\right)$ 여기서 $\mathbf{w}=\boldsymbol{\mu}_i-\boldsymbol{\mu}_j$ and $\mathbf{x}_0=\frac{1}{2}\left(\boldsymbol{\mu}_i+\boldsymbol{\mu}_j\right)-\frac{\sigma^2}{\left\|\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right\|^2} \ln \frac{P\left(\omega_i\right)}{P\left(\omega_j\right)}\left(\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right)$
- 모든 클래스의 공분산 행렬이 동일하다. - 샘플들이 같은 크기와 모양의 초타원체 클러스터에 놓이는 상황에 해당 - $i$ 번째 클래스의 클러스터는 평균 벡터 $\boldsymbol{\mu}_i$ 를 중심으로 한다.
$g_i(x)=-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_{\boldsymbol{i}}\right)^t \boldsymbol{\Sigma}_i^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)-\frac{d}{2} \ln 2 \pi-\frac{1}{2} \ln \left|\boldsymbol{\Sigma}_i\right|+\ln P\left(\omega_i\right)$ $\frac{d}{2} \ln 2 \pi,\left|\boldsymbol{\Sigma}_i\right|$ 가 $i$ 에 대해 독립 $$ \rightarrow g_i(\boldsymbol{x})=-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)^t \boldsymbol{\Sigma}_i^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)-\ln P\left(\omega_i\right) $$ - $i$ 에 독립적인 2차 항 $\boldsymbol{x}^t \boldsymbol{\Sigma}_i^{-1} \boldsymbol{x}$ 를 빼면, $g_i(\boldsymbol{x})=\boldsymbol{w}_i \boldsymbol{x}+\omega_{i 0}$ 여기서 $\boldsymbol{w}_i=\boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_i$ and $\omega_{i 0}=-\frac{1}{2} \boldsymbol{\mu}_i^t \boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_i+\ln P\left(\omega_i\right) $ 이 판별식들은 선형적이므로 그로 인한 경계는 초평면이다. 이 초평면의 경계 식은. $\boldsymbol{w}^t\left(\boldsymbol{x}-\boldsymbol{x}_0\right)=1$ where $\boldsymbol{w}_i=\boldsymbol{\Sigma}^{-1} \boldsymbol{\mu}_i$ and $\boldsymbol{x}_0=\frac{1}{2}\left(\boldsymbol{\mu}_i+\boldsymbol{\mu}_j\right)-\frac{\ln \left[P\left(\omega_i\right) / P\left(\omega_j\right)\right]}{\left(\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right)^t \boldsymbol{\Sigma}^{-1}\left(\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right)}\left(\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right)$ - $\boldsymbol{w}=\boldsymbol{\Sigma}^{-1}\left(\boldsymbol{\mu}_i-\boldsymbol{\mu}_j\right)$ 는 일반적으로 $\boldsymbol{\mu}_i-\boldsymbol{\mu}_j$ 방향이 아니기 때문에 영역을 분리하는 초평면은 일반적으로 이 평균들을 잇는 선에 직교하지 않는다.
Case3: $\Sigma_i=\operatorname{arbitrary}($ (임의적)
- 일반적인 정규분포의 경우 공분산 행렬은 각 부류마다 다르다. $$ \begin{aligned} & g_i(x)=-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)^t \boldsymbol{\Sigma}_i^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_i\right)-\frac{d}{2} \ln 2 \pi-\frac{1}{2} \ln \left|\boldsymbol{\Sigma}_i\right|+\ln P\left(\omega_i\right) \\ & \frac{1}{2} \ln 2 \pi \text { 만이 i에 대해 독립 } \\ & \rightarrow g_i(\boldsymbol{x})=\boldsymbol{x}^t \boldsymbol{W}_i \boldsymbol{x}+\boldsymbol{w}_i^t \boldsymbol{x}+\omega_{i 0^2} \\ & \text { where, } \boldsymbol{W}_i=-\frac{1}{2} \boldsymbol{\Sigma}_i^{-1}, \boldsymbol{w}_i=\boldsymbol{\Sigma}_i^{-1} \boldsymbol{\mu}_i \text { and } \\ & \omega_{i 0}=-\frac{1}{2} \boldsymbol{\mu}_i^t \boldsymbol{\Sigma}_i^{-1} \boldsymbol{\mu}_i-\frac{1}{2} \ln \left|\boldsymbol{\Sigma}_i\right|+\ln P\left(\omega_i\right) \end{aligned} $$
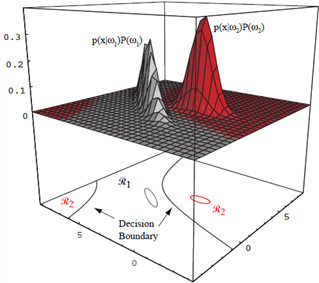
4개의 정규분포에 대한 판정 영역. 경계영역의 모양은 꽤 복잡해질 수 있다.
EXAMPLE1: 2차원 가우스 데이터에 대한 판정 영역
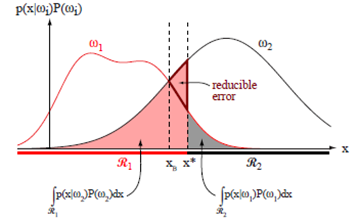
(에러확률과 적분)
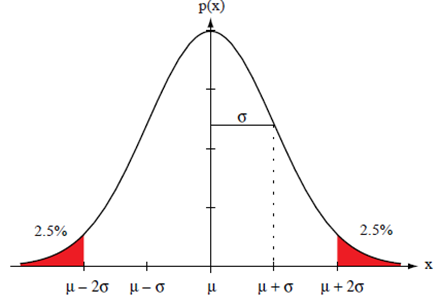
정규 분포의 오차 범위
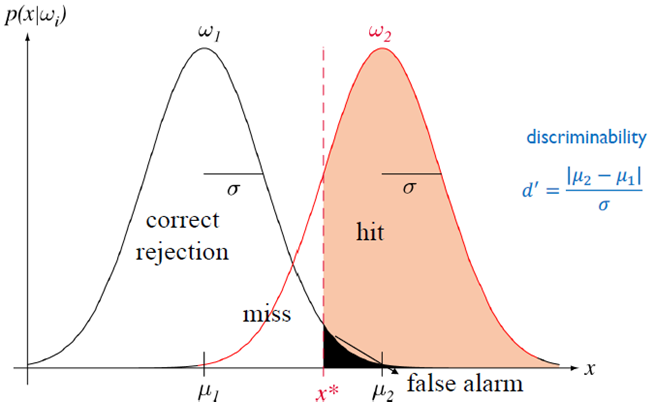
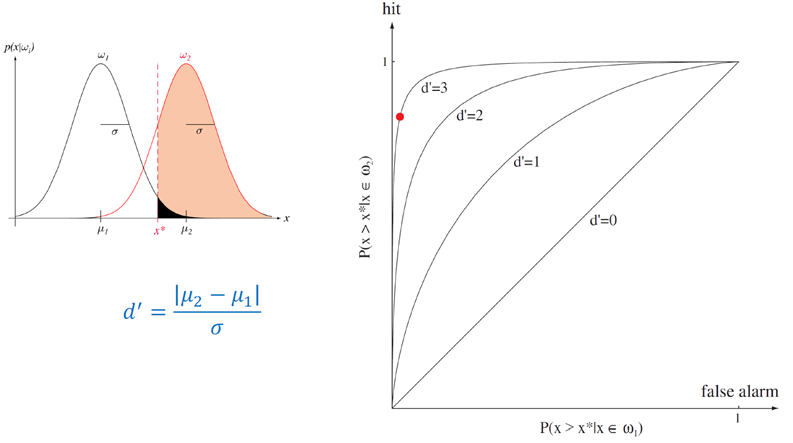
ROC(receiver operation characteristic)(수신기 동작 특성)
횡좌표는 허위 경고 확률이고, 세로 좌표는 히트 확률이다. 여기서는 히트 및 허위 경고율로부터 d’=3을 추론가능
Bayes decision theory-이산적 특징
- 많은 실제 응용에서 구성요소 (특징벡터) x 는 2진, 3진, 또는 더 높은 진수의 정수값을 가지고, $x$ 는 $m$ 개의 이산 값 $v_1, \ldots, v_m$ 중 하나만 취할 수 있다. $$ \int p\left(x \mid \omega_j\right) d x \rightarrow \sum_x P\left(x \mid \omega_j\right) $$
패턴인식의 방법론은 자연계, 특히 인간의 패턴 인식 체계에 대해 실제로 자연계가 이 문제를 어떻게 푸는가에 대한 지식에 영향을 받아 이뤄진다.
1.2 보기
예를 들어 생선 통조림 공장에서 생선을 분류하는 과정을 자동화하기를 원한다고 하자. 생선은 컨베이어 벨트에 실려 지나가며, 광학 센서를 이용해서 Sea bass salmon을 분류할 것이며, 카메라를 설치하여 sample 영상을 얻어 두 어종간의 외형적 차이(길이, 밝기, 폭, 지느러미 수와 모양, 입의 위치 등)을 적다보면, 이중 분류기에 사용할 특징이 나올 것이다. 이때, 영상의 노이즈, 또는 변화(밝기, 컨베이어위의 위치,. 잡영(static))도 주목해야 할 것이다.
그림 1.1분류될 생선은 먼저1. 카메라에 의해 감지되고,2. 전처리를 거친 뒤, Feature를 추출,3. Classification을 거쳐 최종적으로4. Sea Bass, Salmon인지를 추출할 것이다.보통 이 정보의 흐름은 소스로부터 분류기의 방향으로 흐르나, 처리 레벨이 변경될 수도 있고, 단계를 통합하는 경우도 있을 수 있다.
Sea bass와 Salmon의 모집단 간에 차이가 있다는 사실이 주어지면, 이들을 (보통 수학적 형태인 다른 묘사들)모델로 본다.
Pattern classification에서 전체를 지배하는 목표와 방식은 이 모델들의 class를 가정하고, 감지된 data를 처리해서 노이즈를 제거한 뒤, 감지된 모든 pattern에 대해 가장 잘 일치하는 모델을 선택하는 것이다. 전처리 과정에서는 segmentation 연산이 가능한데, 이때, 배경분리, 서로간에 분리가 이뤄진다.
이후 그 정보들이 Feature 추출기로 가면, 어떤 특징, 특성을 측정해서 데이터를 축소한다.
이 값들이 분류기도 가면, 이것들을 평가하고, 최종적으로 어종에 대한 판정을 내린다.
그렇다면 이 특징 추출기와 분류기가 어떻게 설계될 것인가를 고려하자면, 누군가가 Sea bass가 Salmon보다 더 길다고 정보를 알려줬다면, 이 사실은 이 어류에 대한 모델을 제공한 것이다.
모델: Seabass는 어떤 전형적 길이를 가지고, 그 길이는 Salmon보다 크다. 따라서 길이는 분명한 특징이 되며, 생선의 길이 $ l $을 통해 분류를 시도할 수 있을 것이다.
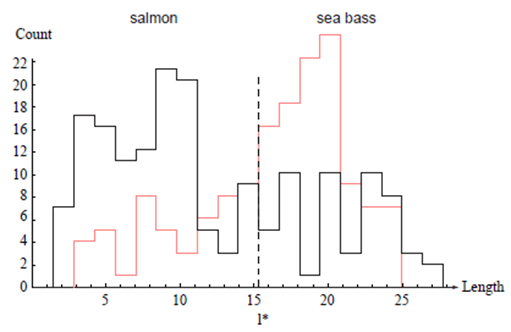
이를 위해 sample을 얻고 측정하고 결과들을 살펴보면 그림 1.2와 같다.
그림 1.2 두 부류의 길이 특징에 대한 히스토그램. * 로 표시된 값이 가장 작은 수의 err을 일으킬 것이다.
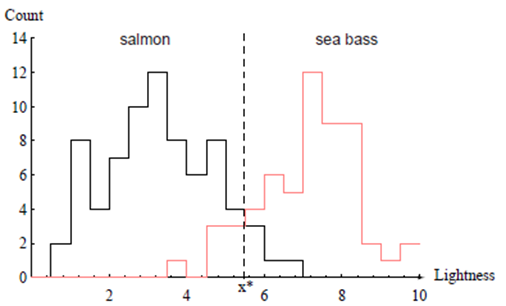
그림 1.3 두 부류의 밝기 특징에 대한 히스토그램. x* 로 표시된 값 하나만으로는 명확한 구분이 어렵다.
그림 1.2에서는 Seabass가 Salmon보다 다소 긴 것을 알려주지만, 사실 신뢰성은 떨어진다.
이번엔, 그림 1.3과 같이 밝기로 시험을 해보니, 상당히 만족스럽게 나옴을 알 수 있다.
다만, 이제까지 분류의 결과들은 비용이 같다고 가정되었다. 예를들어 Salmon을 Seabass로 판정하는 것과 그 역이 동일하다는 것. 하지만, Seamon을 샀는데 Seabass가 들었다면 더 강력한 항의가 있을 것이기에 이 비용은 현실적에서는 맞지 않다.
따라서 decision boundary를 왼쪽으로 더 이동시켜 Salmon으로 분류되는 Seabass의 수를 줄여야 한다. 이는 비용에 따라 더 왼쪽으로 이동할 수도, 오른쪽으로 이동할 수도 있다. 본질적으로 이러한 비용을 최소화하도록 판정경계를 나누는 것이 decision theory의 핵심이다.
판정과 관련된 비용을 알고 있어 최적의 기준 값 x*을 선택했다 해도, 결과가 만족스럽지 않다면, 더 나은 성능을 제공할 방법을 찾아야 한다. 즉, 여러 특징에 의존하게 된다.
이번엔, Seabass가 일반적으로 Salmon보다 폭이 더 넓다는 사실을 이용해보자. 밝기 $x_1$ 과 폭 $x_2$ 를 2차원 특징 공간의 점 또는 vector x로 축소시킨다. $x=\left(\begin{array}{l}x_1 \\ x_2\end{array}\right)$
이제 문제는 이 특징공간을 두 영역으로 나누는 것이고, 한 영역의 모든 점은 Seabass, 다른 영역은 Salmon이 될 것이다. sample에서 그림 1.4의 분포를 얻었다고 하자.
그림 1.4 Seabass와 Salmon의 밝기 및 폭 특징. 직선을 판정경계로 사용할 수 있을 것이다. 분류 에러는 그림1.3보다 낮으나 아직 어느정도 존재한다.
이 결과를 보면, 더 많은 특징을 사용하는 것이 꽤나 바람직하다. 이외에도 등지느러미의 꼭대기 각도, 눈의 배치(입-꼬리까지의 거리에 대한 비)같은 특징을 포함시킬 수 있을 것이다. 다만, 이 특징들은 중복될 수도 있고, 어떤 특징은 성능향상이 없을수도 있으며, 차원의 저주를 야기할 수 있다. 또한 측정 비용도 무시못할 요소이다.
그래서 두 특징들에 판정을 내리도록 강요된다 가정해보자. 만약 모델이 너무 복잡하다면, 그림1.5와 같은 복잡한 판정경계를 갖는다.
그림 1.5 지나치게 복잡한 모델은 복잡한 판정경계를 만들고, sample을 완벽하게 분류하겠지만, 실제로는 과적합으로 낮은 성능을 보일 것이다.
이 경우 sample은 완벽히 분류하겠지만 새로운 패턴에는 정확도가 떨어질 것이다. 이것이 일반화(General-Ization)에 대한 이슈이다. 사실상 그림 1.5는 특정 패턴에 과적합 되어 있다. 해결방법은 더 많은 학습 샘플을 구하는 것이지만, 이게 어려울 때는 다른 방법을 사용해야 한다. 그렇기에 실제 자연은 복잡한 판정경계가 아닐 것이라는 확신을 가지고 단순화한 것이 그림 1.6이다.
그림 1.6 훈련 집합에 대한 성능과 분류기의 단순성 간의 최적 절충(tradeoff)를 나타내고 있다. 이는 새 패턴들에 대해서도 최고의 정확도를 제공할 것이다.
이 경우 새로운 데이터에 더 좋은 결과를 보인다면, sample에 대해 조금 저조해도 만족할 수 있을 것이다. 하지만, 더 간단한 분류기가 좋다는 것을 어떻게 뒷받침할까? 그림 1.4가 1.5보다 좋다고 말할 수 있는가? 이 절충관계를 어떻게든 최적화할 수 있다고 가정하면, 시스템이 모델을 얼마나 잘 일반화할 수 있을것인지를 예측할 수 있는가? 이것이 바로 통계적 패턴 인식의 핵심 문제에 속한다.
우리의 판정은 특정 작업, 비용을 위한 것이며, 범용성을 가지에 만든다는 것은 어려운 도전이다. 기본적으로 분류는 그 패턴들을 만든 모델을 복구하는 작업이기에, 모델의 유형에 따라 분류 기법은 달라질 수 있다. 이러한 기법은 NeuralNet, 통계적 인식, 구문론적 패턴 인식 등 다양한 방법이 있다. 다만 거이 모든 문제에서의 중점은 구성성분간 구조적 관계가 간단하고 자연스레 드러나며, 패턴의 전형적 모델이 나타내질 수 있는 좋은 표현을 달성하는 것이다. 경우에 따라 패턴들은 실수값의 vector, 정렬된 속성, 관계에 대한 표사로 표현될 것인데, 어쨌든 비슷한 애들끼리는 서로 가까이 있고, 다른 애들끼리는 멀리 있게 되는 표현을 찾는 문제라 할 수 있다.